
Debugging RAG systems

In my previous post - https://shchegrikovich.substack.com/p/zoo-of-rags - I described several architectures for building RAG systems. In this post, I want to cover problems in the operation of RAG systems.
The debugging process consists of steps: a problem occurs in the system, a hypothesis is formulated, the hypothesis is checked, and the problem is fixed. The most important step is the formulation of a hypothesis. To create a good hypothesis, we need to understand what can go wrong in the system.
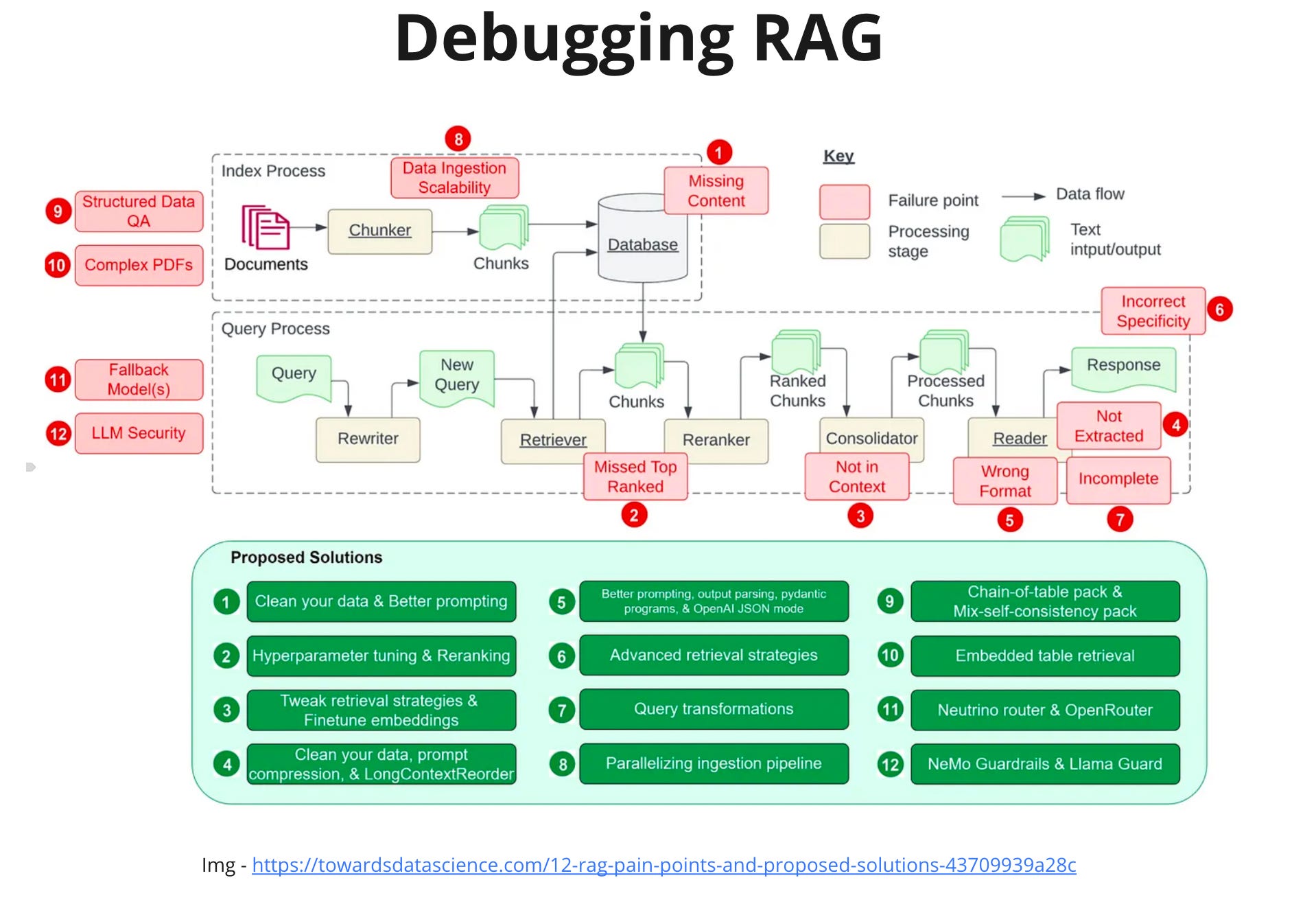
An excellent overview of RAG problems can be found here https://towardsdatascience.com/12-rag-pain-points-and-proposed-solutions-43709939a28c - 12 RAG Pain Points and Proposed Solutions. All problems with RAG can be split into several buckets: Indexing, Searching and Prompting. These buckets correspond to three main stages of the RAG pipeline. To identify these problems, a logging and monitoring infrastructure needs to be built.
Indexing problems related to extracting and chunking information. First, we must ensure we've got all the required information for the application. But even if we have all the information, sometimes it's present in different formats. Parsing complex PDFs, images, and tables can be problematic. Two tools help with observability at this stage: https://github.com/gabrielchua/RAGxplorer and https://huggingface.co/spaces/m-ric/chunk_visualizer. RAGxplorer can answer why specific chunks were returned, whereas chunk_visualizer will help with chunk size and strategies experiments.
Searching issues occur during retrieval and ranking. For the user's request, we need to retrieve the most accurate documents from the index, taking into account the intent of the request. The RAG can not only miss documents in the index but can also fail to rank them appropriately.
In the Prompting category, there are problems with grounding LLMs and creating prompts. Retrieved documents or chunks need to be correctly added to a prompt. Due to the context window limit, we can not include all the documents. There are also problems related to the proper formatting of the output and the fullness of the answer.
To identify problems from the category Searching and Prompting, we can use - https://github.com/Helicone/helicone - an open-source solution for logging, caching, tracking costs and retries. In the simplest case, we can use the ELK stack for logging and monitoring.
Resources:
https://towardsdatascience.com/12-rag-pain-points-and-proposed-solutions-43709939a28c - 12 RAG Pain Points and Proposed Solutions
https://arxiv.org/abs/2401.05856 - Seven Failure Points When Engineering a Retrieval Augmented Generation System

Video - LlamaIndex Sessions: Practical Tips and Tricks for Productionizing RAG (feat. Sisil @ Jasper)
https://github.com/Helicone/helicone - Open-source observability platform for LLMs