


Your AI Agent needs a new brain - Large Action Model

LLMs are fantastic at generating texts, but this is not enough when we talk about AI Agents. Suppose we want to write an email. LLM will provide us with a nice response but won't be able to send an email. To actually send the response many agents rely on function calling. In this case, we pass descriptions of several functions to LLM and ask which of these functions we need to call in order to help the user. Most likely it will be send_email(body='Hi, …', subject='RE: …', to='').
Large Action Model (LAM) is a Large Language Model which is really good at function calling. In other words, LAM provides a complete workflow to solve a user's request. One implementation of this idea is the xLAM family of models from Salesforce. This model took third place on the Berkeley Function-Calling Leaderboard. The family has several models, ranging from 1B to 141B parameters. The 1B model is fine-tuned DeepSeek-Coder model, 8x22B model is fine-tuned Mistral.

Fine-tuned models for functional calling are not a new thing. IBM delivered the API-BLEND dataset and GRANITE-20B-FUNCTIONCALLING model earlier this year. API-BLEND is built from 10 different datasets and consists of 190k records. So GRANITE-20B-FUNCTIONCALLING model is a fine-tuned version of GRANITE-20B-CODEINSTRUCT.
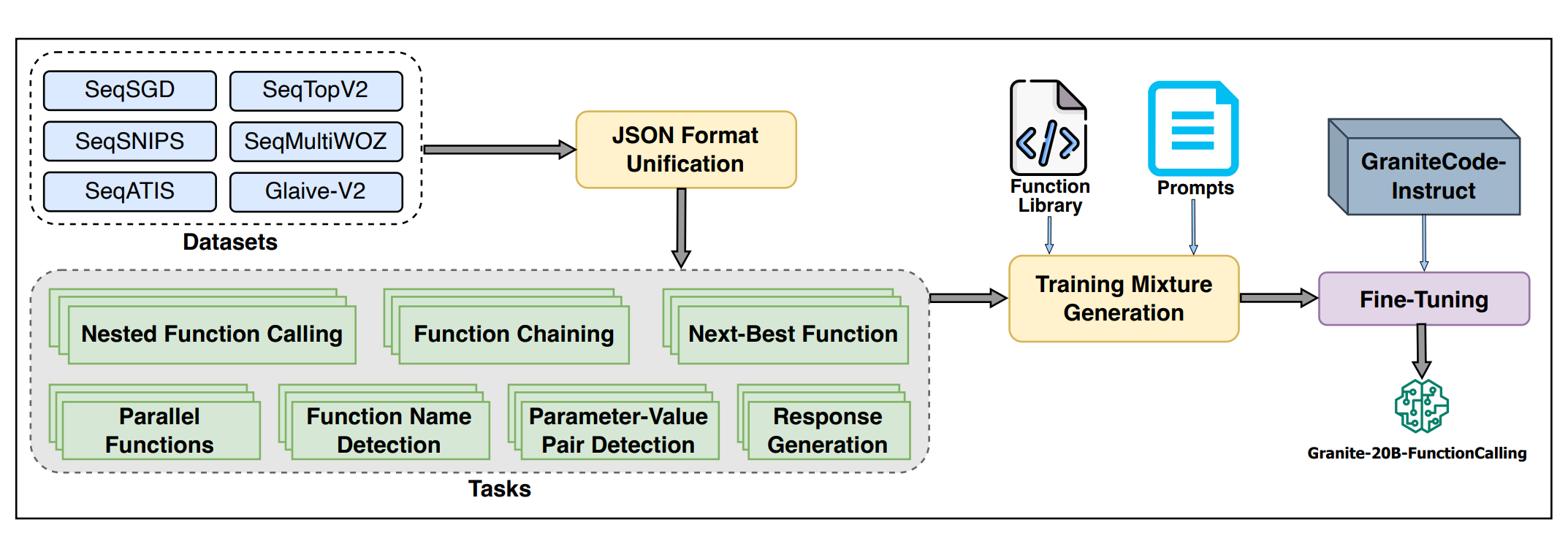
Fine-tuning is not hard, but fine-tuning for functional calling can be challenging because it consists of 7 different tasks: Nested Function Calling, Function Chaining, Next-Best Function, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection and Response Generation. As a result, we need to apply multi-task learning techniques. On the other hand, validation is much simplified in this fine-tuning process. When we receive results from LLM, we can check them with rule-based validation. In the simplest case, we can try to simulate the execution of received functions. Simplified validation makes it a perfect candidate for synthetic data generation.
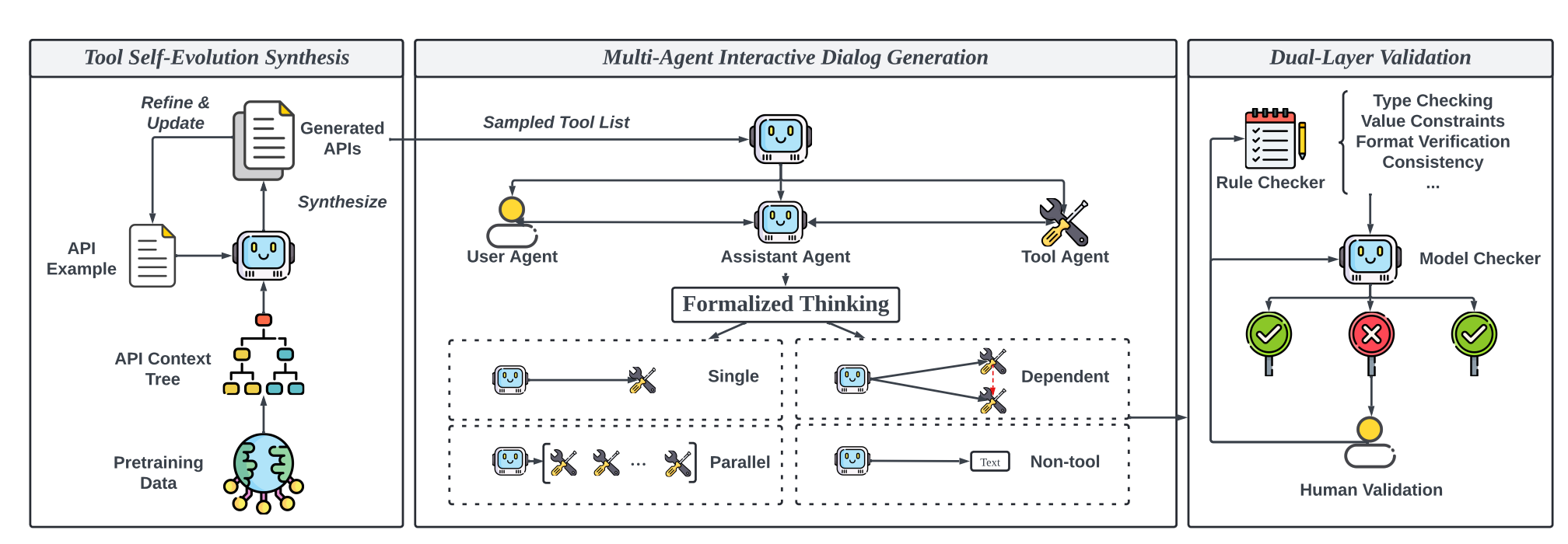
The ToolACE paper presents a pipeline for generating a high-quality synthetic dataset for functional calling. The pipeline consists of 3 steps: Tool Self-Evolution Synthesis, Multi-Agent Interactive Dialog Generation and Dual-Layer Validation. The process starts with building the API Context Tree; this tree represents different domains such as finance or health. Then, these domains are used to generate new API examples. Once new API examples are ready, the Multi-Agent component generates dialogues. The Multi-Agent Interactive Dialog Generation uses participants: user, assistant, and tool. These three actors communicate to produce high-quality data. The verification process uses a rule-based approach, LLM as a judge and human feedback.
It looks like functional calling can be replaced with code generation. LLMs are very good at code generation, so why do we need this different feature? Despite all the similarities, there are a few differences. Functional calling is safer, less error-prone, fixed in scope, and faster compared to code generation.
Resources:
https://arxiv.org/abs/2409.03215 - xLAM: A Family of Large Action Models to Empower AI Agent Systems
https://www.leewayhertz.com/actionable-ai-large-action-models/ - Actionable AI: An evolution from Large Language Models to Large Action Models
https://medium.com/version-1/the-rise-of-large-action-models-lams-how-ai-can-understand-and-execute-human-intentions-f59c8e78bc09 - The Rise of Large Action Models, LAMs: How AI Can Understand and Execute Human Intentions?
https://arxiv.org/abs/2409.00920 - ToolACE: Winning the Points of LLM Function Calling
https://arxiv.org/abs/2407.00121 - Granite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
https://arxiv.org/abs/2402.15491 - API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs
https://blog.salesforceairesearch.com/xlam-large-action-models/ - Actions Speak Louder Than Words: Introducing xLAM, Salesforce’s family of Large Action Models
https://gorilla.cs.berkeley.edu/leaderboard.html - Berkeley Function-Calling Leaderboard