


Truly open LLMs

To make an LLM a truly open one, one needs not only to publish weights but also data and training receipts. There are many open-weight models with a free-to-use licence, but just a few of them share data pipelines and training recipes. Among them are LLM360 K2, OLMo 2 and MAP-Neo.
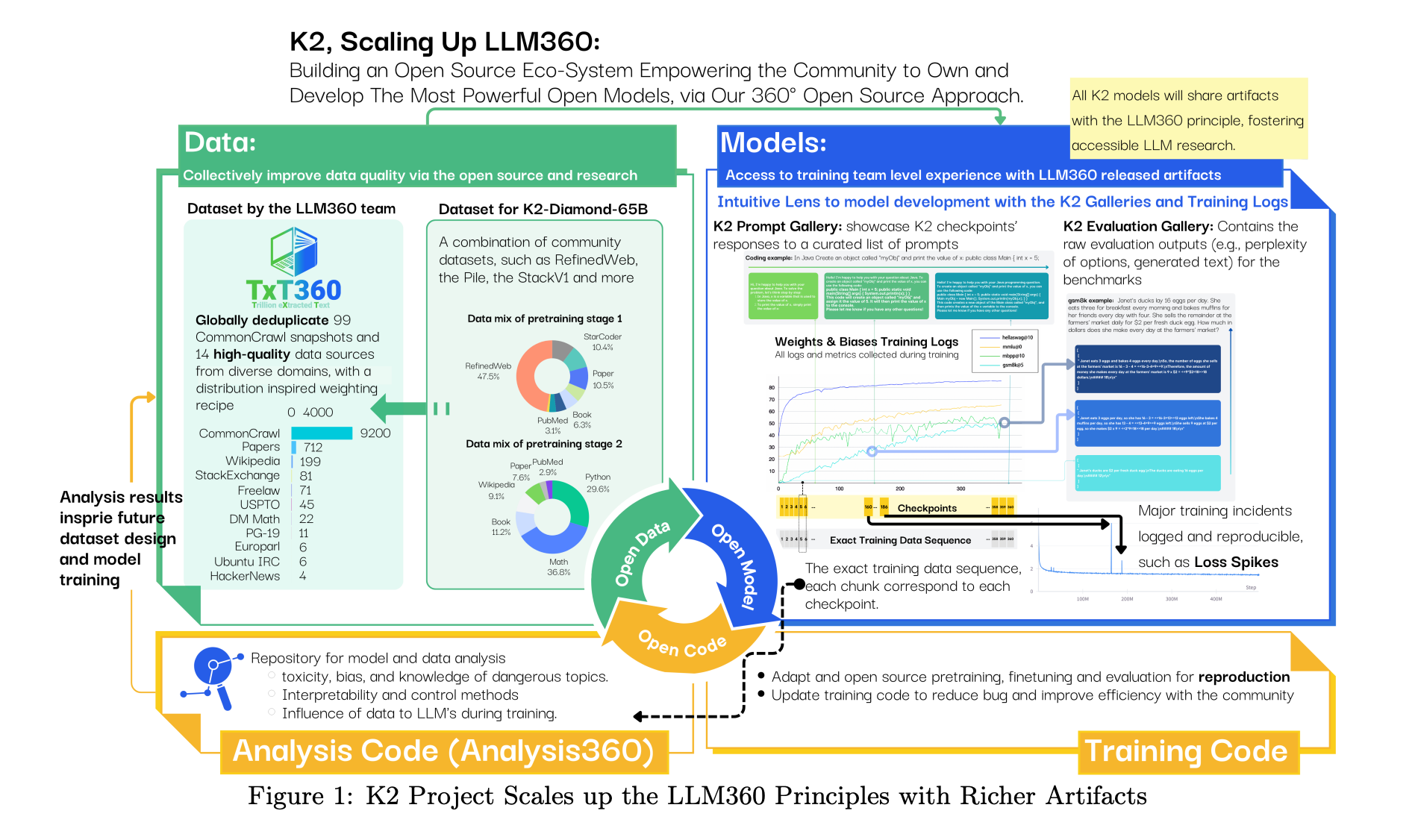
When authors share model weights, data, and training code, it allows the community to take a sneak peek behind the doors and explore lesser-known problems in the space, such as loss spikes, running massive GPU clusters, and the frameworks used.
LLM360 and MAP-Neo use Megatron from NVIDIA for training models. It consists of Megatron-Core (a highly optimised GPU library for training transformers) and Megatron-LM (a framework that uses Core for training LLMs). For MAP-Neo Megatron, increased performance from 6400 TPS to 7200 TPS, due to model and data parallelism techniques. As a training framework, OLMO 2 uses PyTorch and Beaker as a workload scheduler. During the training, every node must run each training step in sync with the other nodes. The whole process runs as fast as the slowest node. Python has an automatic garbage collector, which can pause a process for some time. In a distributed system, it means that every node can be randomly paused. OLMO2 runs GC in a Python process at specific time intervals on all machines simultaneously and disables automatic GC. In addition, for the data curation pipeline, OLMO uses a Spark cluster.
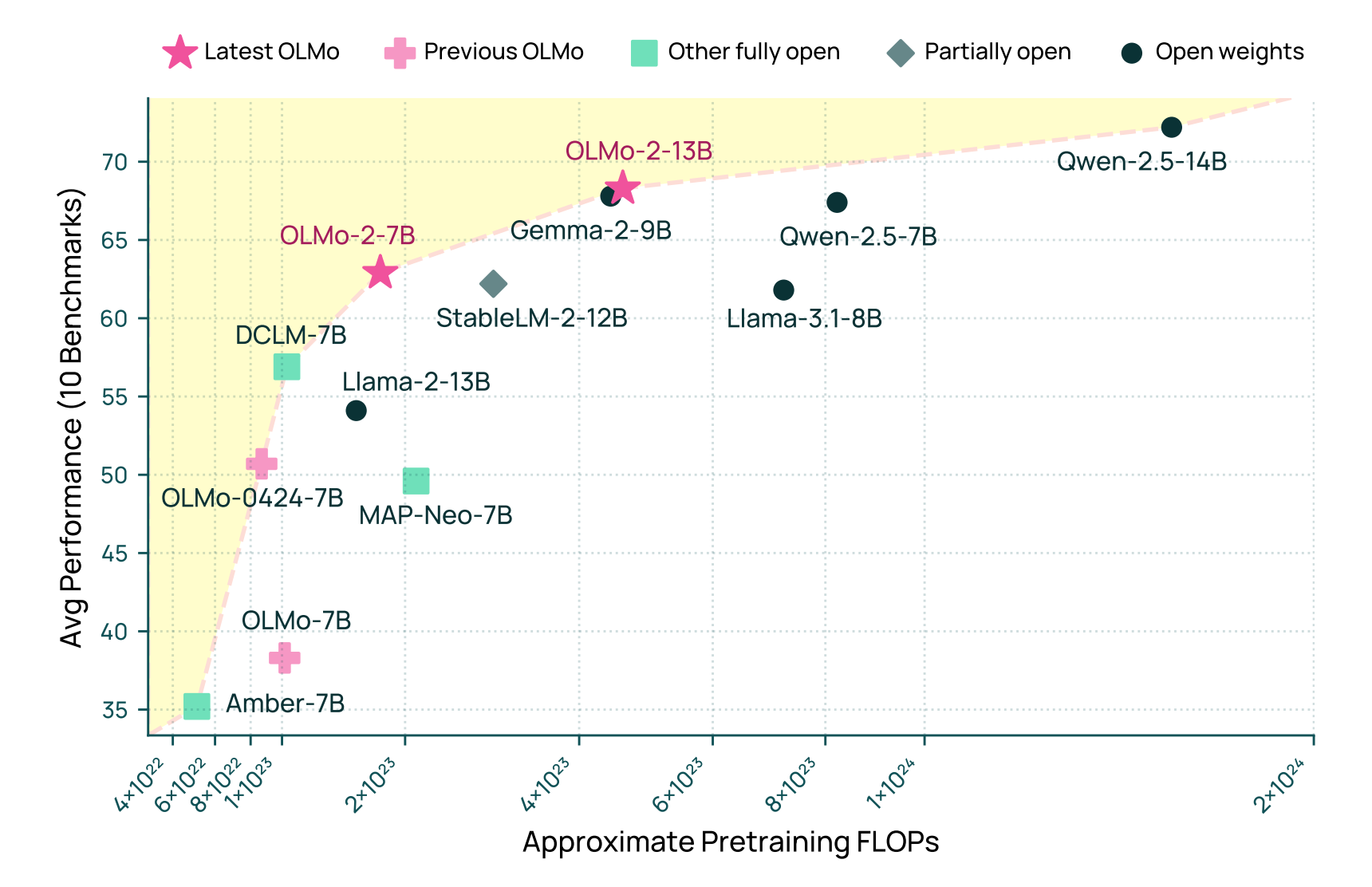
LLM360 utilises NVIDIA GPU Cloud (NGC) for its cluster of 480 A100 GPUs, which features 411 TB of disk space. Four nodes are used as backup nodes for a replacement. OLMO uses two clusters(Google Cloud and Cirrascale Cloud Services) with 1000 H100 GPUs. MAP-Neo 512 H800 GPUs across 64 nodes.
Another area highlighted in the report is the occurrence of loss spikes. Loss spike is an example of training instability, which manifests itself as a sudden increase in training loss. There are several strategies to work with them. Continue if it recovers itself, or start from the previously saved checkpoint. The papers review this problem and propose several solutions. The solutions are removing repeated n-grams, updated initialisation schema, RMSNorm, Reordered norm, QK-norm and others.
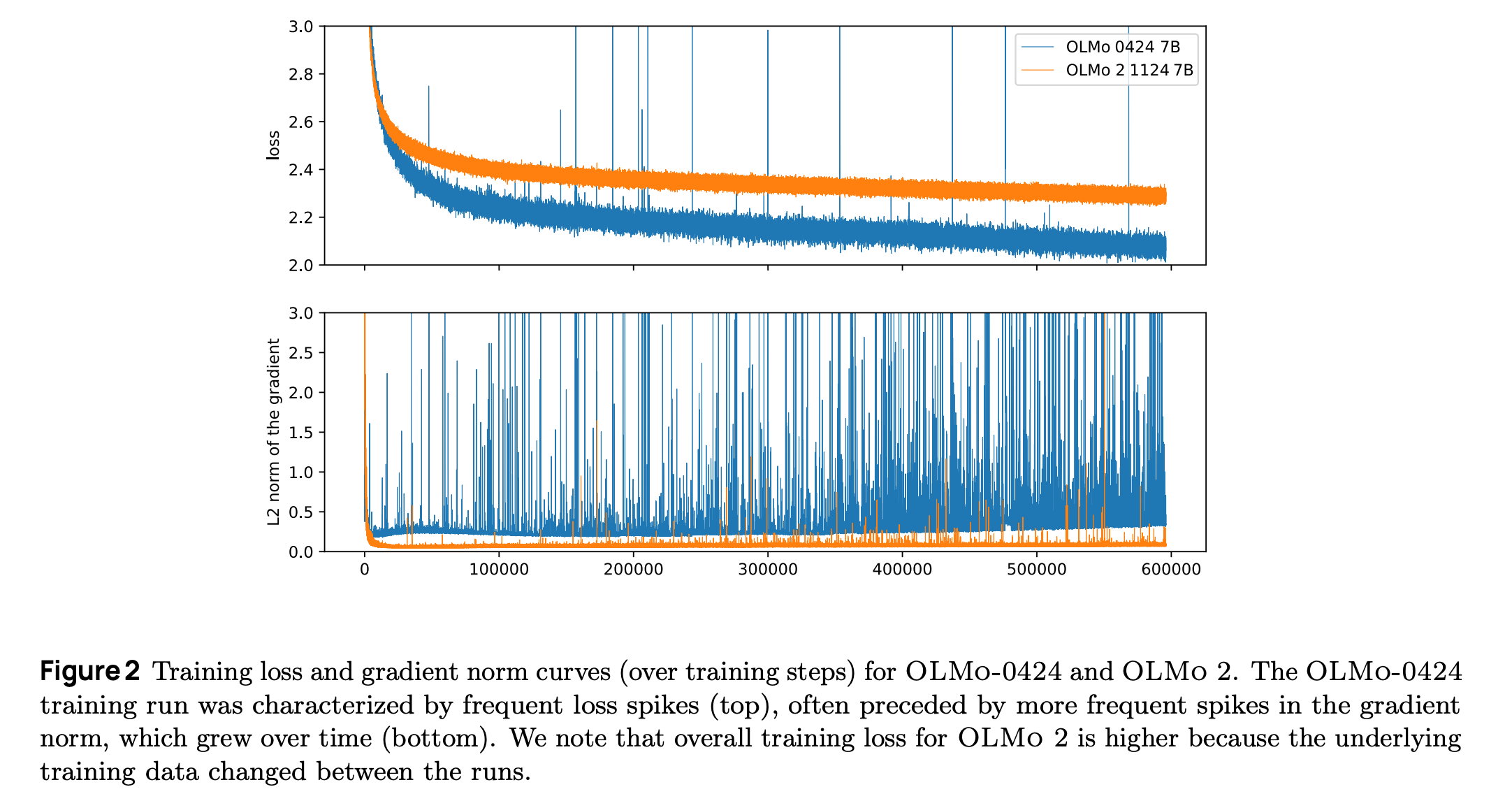
Resources:
Paper: 2 OLMo 2 Furious - https://arxiv.org/abs/2501.00656
Paper: LLM360 K2 - https://arxiv.org/abs/2501.07124
Paper: MAP-Neo - https://arxiv.org/abs/2405.19327