
Time to replace Large Language Models or why o1 is a big deal

OpenAI has released o1. Along with the release, OpenAI has updated a capabilities section. To the existing list of capabilities, including text generation, vision, function calling, and structured output, the fifth element was added - reasoning. This surprised me a bit—didn't we have it for quite some time with the first release of ChatGPT 3.5? Some people say that we've made a transition from large language models to large reasoning models. What is it all about?
The model's documentation highlights two examples. The first shows how to use o1-preview for data validation, and the second describes the process of improving support AI Agents via detailed routine generation. Both examples show that the new capability helps the model excel in tasks where advanced reasoning capabilities are required with minimum human intervention.
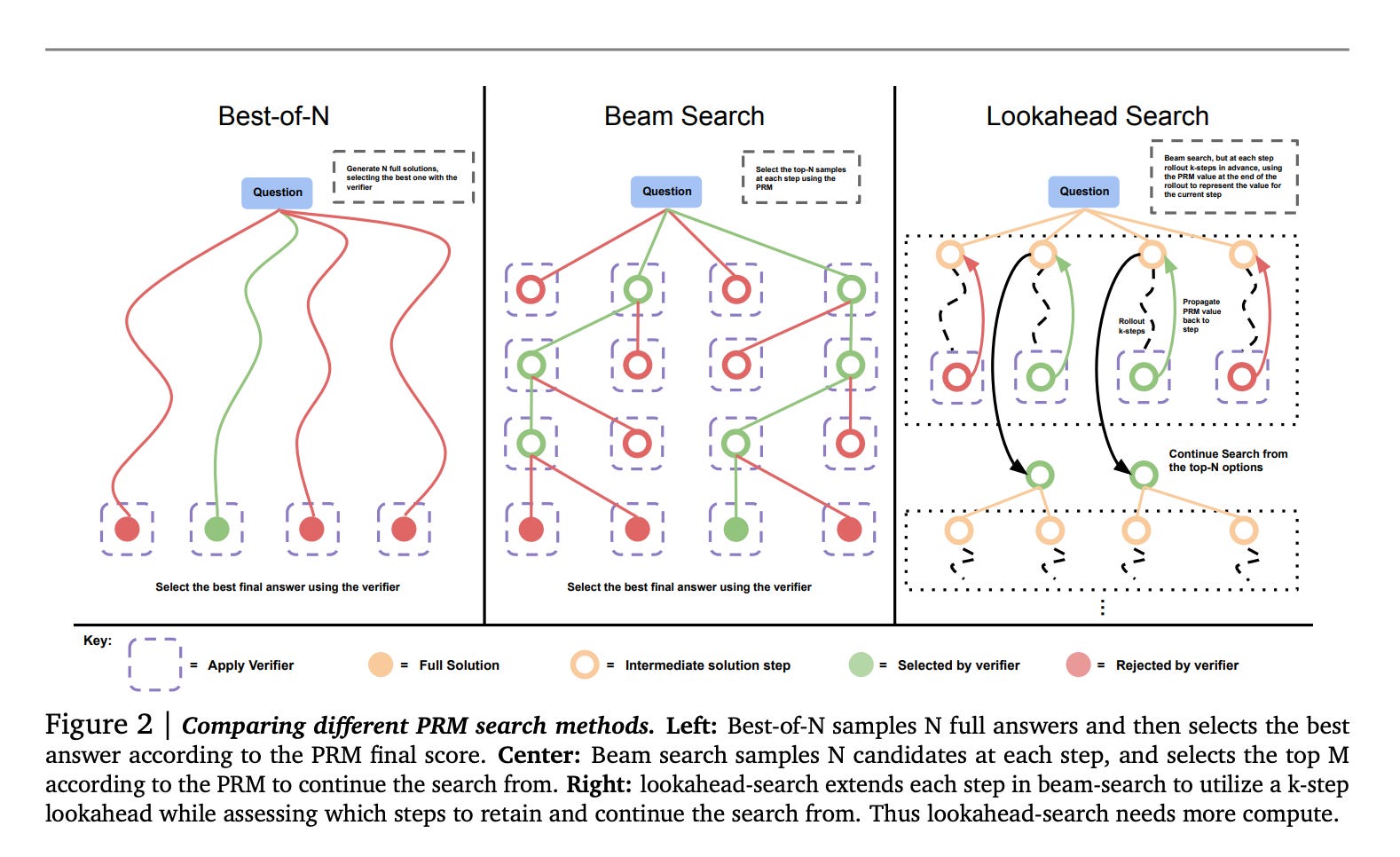
It's not clear how o1 was developed, but Google recently published a paper with some experiments on LLM's scaling. The main idea is to give the model more time to think. There are different strategies for giving the model more time to think, but the simplest is to generate several answers and choose the best based on the verifier or reward model. I would recommend looking at the paper "Large Language Monkeys", which covers the same topic. The paper states that it's possible to solve 56% of tasks from SWE-bench Lite by generating 250 answers instead of 1. With only one sample, the results are more modest, 15.9%. This is why o1 is slow - it does a lot of "thinking".

From a boarder perspective, it means that new scaling mechanics have been discovered in LLMs. Previously, we relied on a huge amount of data and computing resources during pre-training. But once the model is released, it's done; there's nothing more we can do about it. The game has changed. Now, we can invest many resources in inference and continue scaling to some extent. The papers I mentioned above say there is a limit to this, too.
Small language models are unexpected winners from inference time scaling. Google's paper states, 'in some settings, it is more effective to pre-train smaller models with less compute, and then apply test-time compute to improve model outputs'. Is it time to change the name to Large Reasoning Models?
References:
https://arxiv.org/abs/2409.13373 - LLMs Still Can't Plan; Can LRMs? A Preliminary Evaluation of OpenAI's o1 on PlanBench
https://arxiv.org/abs/2408.03314 - Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
https://arxiv.org/abs/2407.21787 - Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
https://openai.com/index/learning-to-reason-with-llms/ - Learning to Reason with LLMs
https://cookbook.openai.com/examples/o1/using_reasoning_for_routine_generation - Using reasoning for routine generation
https://cookbook.openai.com/examples/o1/using_reasoning_for_data_validation - Using reasoning for data validation
https://platform.openai.com/docs/guides/reasoning - Reasoning Models
