
Three ways to evaluate AI Agents

LLM evaluation is complex; agent evaluation is even more complicated. The biggest problem is that AI Agents execute a sequence of actions. They need to understand, plan and eventually execute. All these three stages might contain multiple rounds or steps inside. From another perspective, we can always check the work's result by evaluating the artefacts that have been produced.
The first way is to check the result of the AI Agent's execution. This is what was covered in the MLE-bench paper. The paper reviews ML agents automating machine learning engineering (MLE) tasks. The idea was brought from the Kaggle competition. In a nutshell, MLE-bench works as an offline Kaggle competition environment. Target AI Agent receive a task, which can be one of 75 competitions from Kaggle, and then the agent generates a submission, which is a CSV file. The submission is evaluated by grading code, which is unique for each task, to calculate a raw score. Based on grading, the agent wins gold, silver or bronze medals.
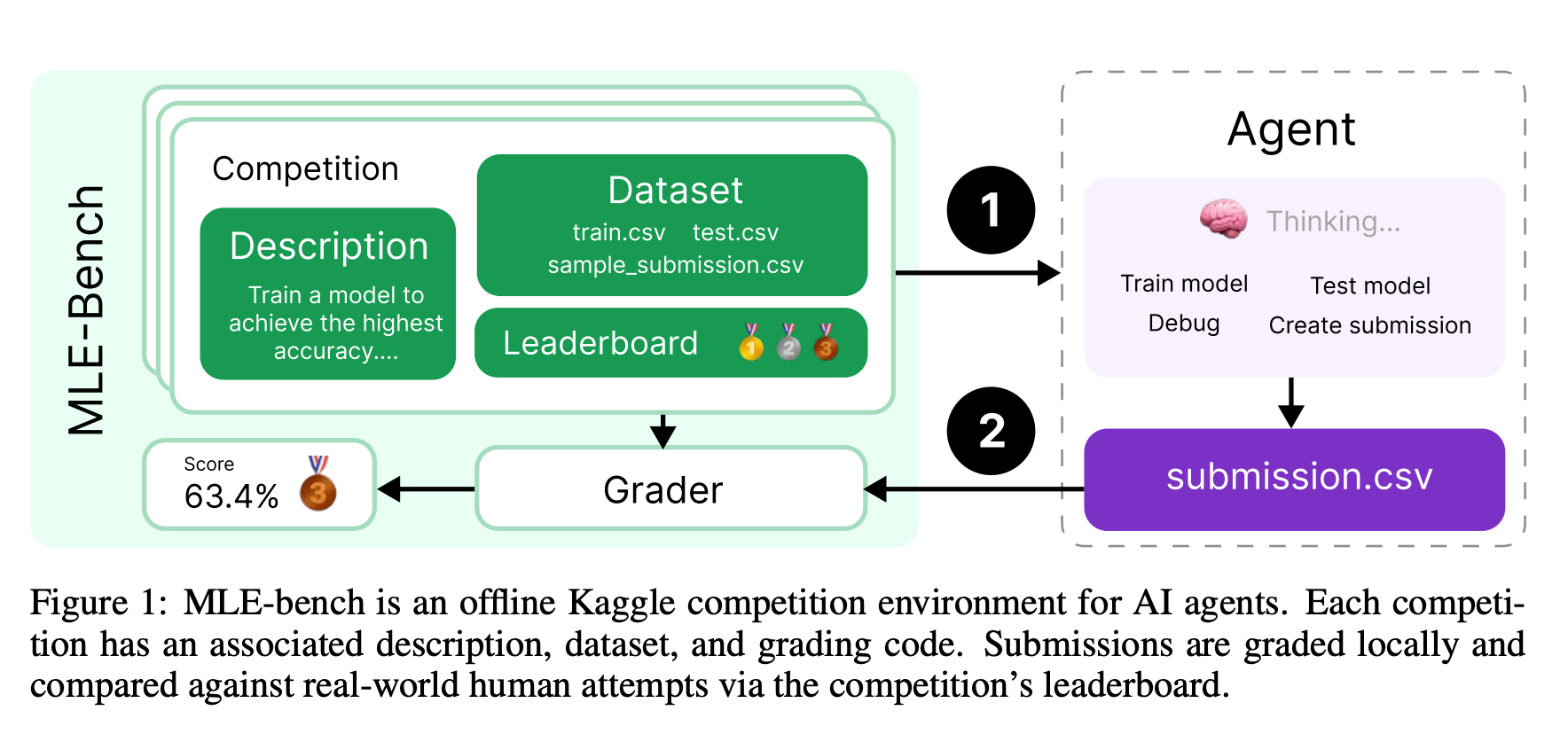
MLE-bench focuses on ML tasks, so the expected result is a working model, not the output from AI Agent. Apart from this rule, there is also a risk of plagiarism. To detect rule-breaking agents and plagiarism, the MLE bench analyses the execution logs of AI Agents and uses the Dolod tool to detect code duplicates. I highly recommend checking out the code for this paper. Inside the repository, you can find AIDE, OpenHands and MLAgentBecnh agents. From the results, o1-preview won the gold medal in 9.4% of cases. Also, the agents were allowed to optimize the code for up to 24 hours per competition.

The second way is to analyse workflow generation. Instead of evaluating artefacts as in the first approach, we can focus on checking how AI agents think or plan. Planning in AI Agents can be complex, so we need steps which the AI Agent wants to execute and dependencies among them in the form of a graph (DAG). The WorFBewnch paper consists of a dataset with scenarios and workflow evaluation code for matching generated graphs. The framework sends the AI Agent a task with tools to use and expects to receive the predicted node chain and graph. The node chain is a list of actions the agent plans to use, and the graph defines the execution flow. The graph can represented in a text form in a simple edge notation: (START, 1) (1, 2) (2, END).

The third approach is Agent-as-a-Judge for other AI Agents. The paper which Meta proposed is based on the idea of LLM-as-a-Judge. The biggest difference between LLM- and Agent-as-a-Judge is that the latter is an agent, which means it's not just a prompt that rates two responses; it's a system of components. The paper proposes an Agent consisting of 8 components: graph, locate, search, retrieve, read, ask, planning and memory. All these components help the Agent-as-a-Judge evaluate coding agents, which is the paper's main focus. The Agent-as-a-Judge starts from the input: an initial task and requirements for the result. The planning component prepares the plan and executes it step by step. The goal of the plan is to check each requirement and find evidence.

Agent-as-a-Judge outperforms LLM-as-a-Judge. Alignment is comparable to Human-as-a-Judge 90% vs 94%, where LLM gives only 60%.

References:
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering - https://arxiv.org/abs/2410.07095
Benchmarking Agentic Workflow Generation - https://arxiv.org/abs/2410.07869
Agent-as-a-Judge: Evaluate Agents with Agents - https://arxiv.org/abs/2410.10934