
Three prompt compression methods to save time and money

The best optimization method is not to make your algorithm 10x faster but to remove waste. For instance, in the LLM world, you submit a prompt to LLM and expect the model to produce the desired output. The model processes tokens from the input sequence and generates an output sequence of tokens. For all these tokens, we pay a service charge fee. Another aspect is the latency - the longer the context, the higher the latency, which delays users from receiving the value. Compression methods help to reduce tokens and, as a result, reduce latency and save some money.

The Selective Context method achieves a 32% reduction in inference time, 36% in inference memory and 50% in context cost without sacrificing performance too much. The basic idea behind this method is that written language carries more information than is needed for understanding. Example: "Do you like tea? Yes, I do like tea". Some people say that just saying yes is sufficient for this question. Now, the task is to find words that do not add much meaning and remove them.
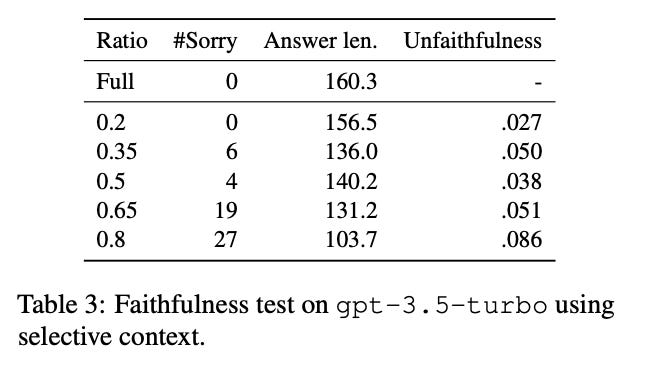
The method works on a lexical unit, which can be a token, a phrase or a sentence. It calculates self-information (measuring how much information the token adds) for each token. Next, we calculate self-information for lexical units. The last step is to remove extra lexical units based on threshold or percentile. To calculate the self-information score, we can use a small language model, which returns probabilities for each token, and use these probabilities as scores.
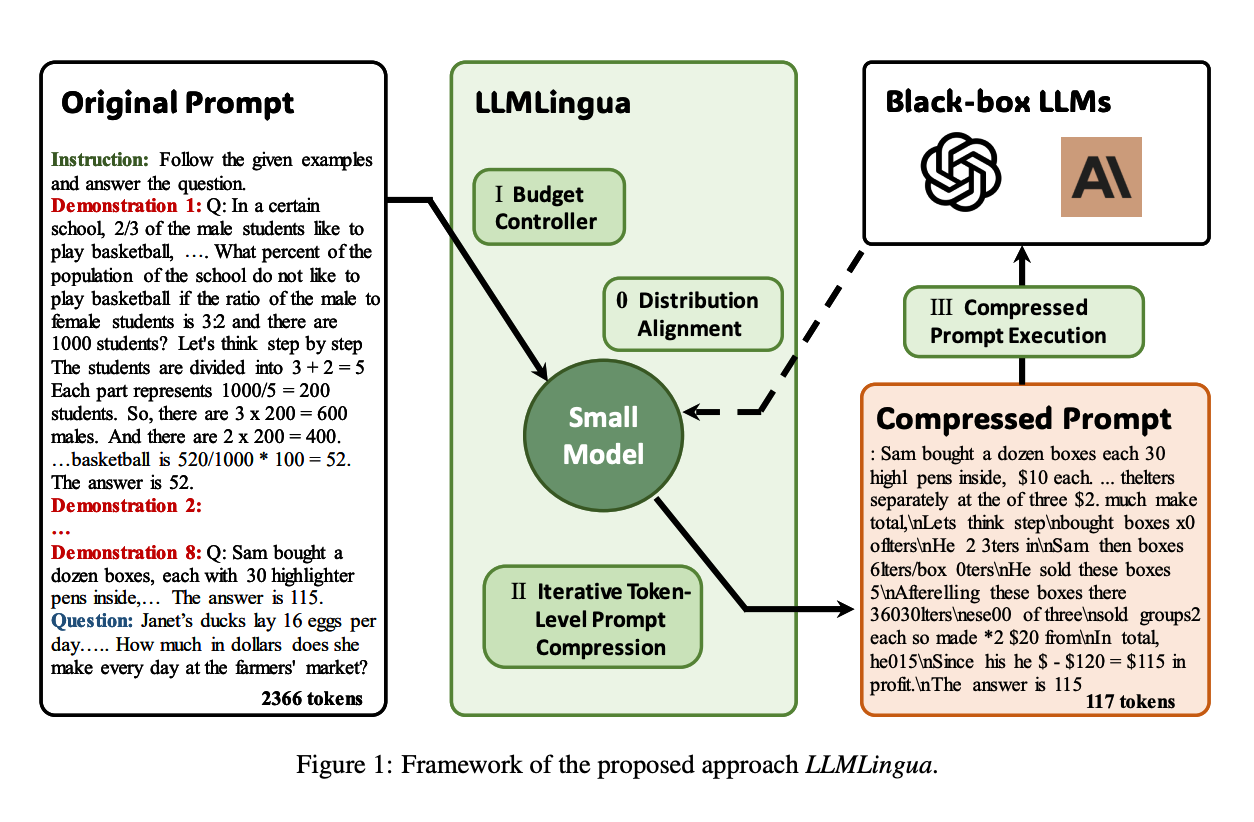
The limit is not just a 50% improvement. Microsoft's LLMLingua can compress prompts by 20x. LLMLingua is based on the same idea as the Selective Context method but with a few additions: it dynamically chooses compression ratios for different components(Instruction, Demonstration, and Question—these components will be compressed using different ratios), uses an improved compression algorithm to keep the most important information, and uses instruction tuning to align a small language model, which is used for calculating probabilities, with the target large language model.
As in the first method, LLMLingua uses a different model to calculate the probabilities of each token - a small language model. If the SML is from a different family than the target LLM: phi4 and GPT-4o or GPT2-Alpaca and Claude-v1.3, then we need to align models. This alignment will ensure that the probabilities of SML are close enough to what the target LLM can produce. LLMLingua does this via instruction fine-tuning the data from the target LLM. The improved compression algorithm does not compress a prompt in one go; it splits the prompt into parts. Information from previous parts is used to do compression of the next part - this guarantees that we do not lose too much valuable information.

LLMLingua is a task-aware compression, and LLMLingua-2 is a task-agnostic, which means a more generic compression method. Compared to the previous two methods, this is the model. They specially designed a data set for training a new transformer-based model, with an objective to classify input tokens as preserve or discard. This method works 3x-6x times better.
Resources:
Paper: Compressing Context to Enhance Inference Efficiency of Large Language Models - https://arxiv.org/abs/2310.06201
Paper: LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models - https://arxiv.org/abs/2310.05736
Paper: LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression - https://arxiv.org/abs/2403.12968