
New approaches in RLHF

Reinforcement learning from human feedback(RLHF) is used to align LLMs. Without it, LLMs will produce unsafe content. An aligned model generates desired responses. The first part of the RLHF process is creating a reward model, which knows how to evaluate and rank responses during training. Based on the feedback from the reward model we optimize LLM's parameters. Depending on the type of algorithm used in RLHF we might need several modes. For instance PPO(proximal policy optimization) requires four components - actor, critic, reward and reference.
Meta has presented a new method - CGPO (Constrained Generative Policy Optimization) in the paper "The Perfect Blend: Redefining RLHF with Mixture of Judges". When a new model is trained it's normally trained on several tasks. This is called multi-task learning(MTL). MTL needs to take into account two things - a reward model is an imperfect proxy of human preferences, which might lead to overoptimization and eventually reward hacking, and different tasks might have contradictory goals.
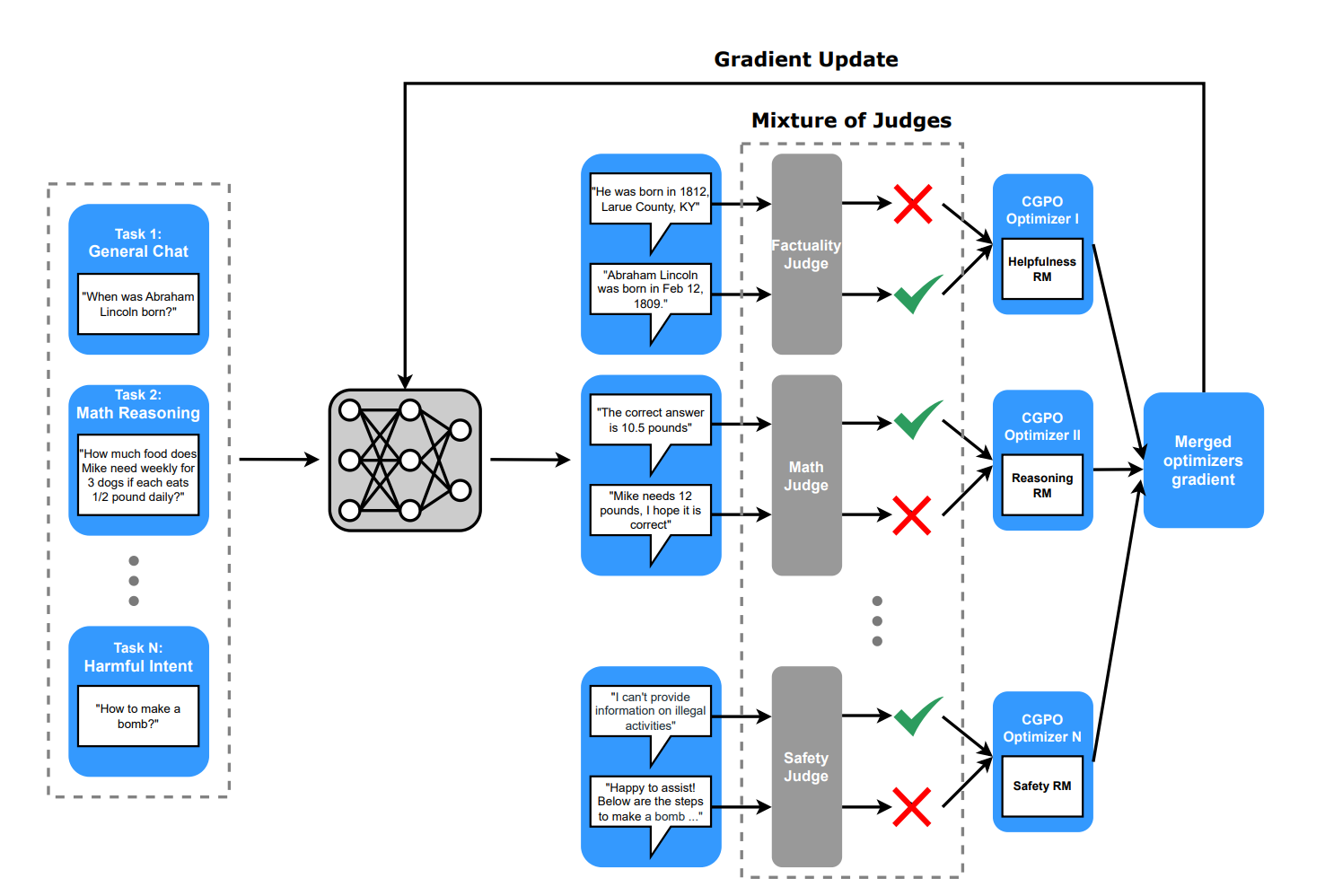
CGPO introduced the idea of judges in the RLHF process. Specifically, CGPO added two types of judges: ruled-based and LLM-based. The rule-based judge checks the response to make sure it precisely follows instructions, such as length requirements or the presence of specific words. It uses string matching and code execution. The LLM-based judge is responsible for more complex checks, such as factuality or safety violations. LLM-based judge internally calls a different LLM, which can be fine-tuned or not.
CGPO splits all prompts based on tasks. For each task, a different pair of judges is implemented. Collaboration of judges helps to identify reward hacks earlier. By handling each task independently, we completely eliminate the problem of contractionary goals. On different benchmarks, CGPO is better than PPO by 2%—7%.
From the Meta's paper we see that RLHF is not only about predicating what people think about the subject, it's also about formal rules and validations. The similar ideas were proposed in the RLEF paper. The paper is focused on code generation.
Reinforcement learning with execution feedback works as this. We ask a model to generate a code. Once the code is generated, we use a public set of tests. If tests don't pass, we prompt the model again with test results(execution feedback). When all public tests are passed, or we reach the limit, we run private tests and use PPO to optimize a model with feedback from private tests. We need private tests for two reasons. The first reason is to prevent the model from cheating. The second reason is that some tests might be computationally expensive to run in the loop.

The last thing to mention is OpenRLHF a github project. The framework supports all popular RLHF optimizations and integrated with Ray, vLLM, DeepSpeed and HF Transformers.
References:
https://arxiv.org/abs/2405.11143 - OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
https://arxiv.org/abs/2409.20370 - The Perfect Blend: Redefining RLHF with Mixture of Judges
https://arxiv.org/abs/2410.02089 - RLEF: GROUNDING CODE LLMS IN EXECUTION FEEDBACK WITH REINFORCEMENT LEARNING
https://github.com/OpenRLHF/OpenRLHF - An Easy-to-use, Scalable and High-performance RLHF Framework