
Mamba as an alternative architecture to LLM Transformers
ChatGPT and many other LLMs are built on top of Transformers architecture, which dominates today. The Mamba model provides an alternative to this.

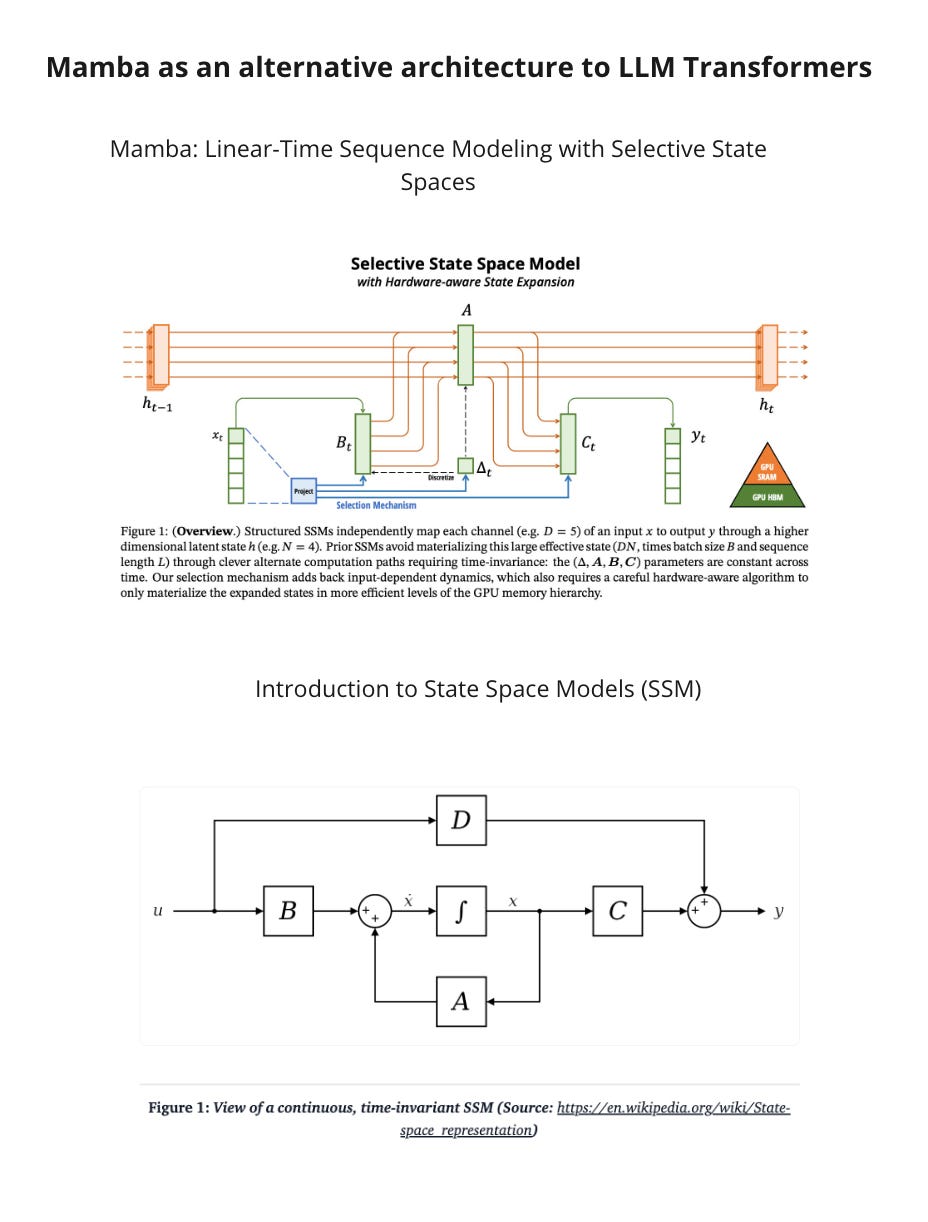
The core of the Mamba model is the S4 - Structured State Space sequence model. What S4 does is predict the next token based on input and a hidden state. The hidden state stores information about previous tokens, which is the main difference to Transformers. Models with hidden states have been known for a long time (RNN, GRU and LTSM); the innovation of S4 is that it's now possible to do training and inference at a scale needed for LLMs. In other words, S4 beat its sequential nature by replacing it with parallel execution.
There are some very interesting mathematical tricks inside S4, but the main idea was to split it into two modes—one for training and another for inference. When we train the model, S4 behaves like a CNN (Convolutional Neural Network), and during inference, it behaves like a RNN(Recurrent Neural Network). CNN scales very well in the training phase but is bad for inference. RNN, on the other hand, scales better inference.
The Mamba model enhanced S4's ideas with selectivity and hardware-aware implementation. Selectivity means that Mamba learns not only the relation between an input token, hidden state, and the next token but also understands the importance of input tokens. Using the specifics of modern hardware, the authors of Mamba enhanced RNN mode in S4 in the same way that FlashAttention in Transformers works.
Applying all of it, Mamba outperforms Transformers, scales linearly during training, produces tokens with constant time per step, and has a really big content window length. The next stop for all new LLM models is to add a Mixture of Expert (MoE) - MoE-Mamba. To me really impressive was to use Transformers, S4 and MoE into one model, that's how Jamba was born.
Transformers can not linearly scale context length; it requires quadratic scaling with respect to the context window length. But S4 can. As a result, it might be possible to build a token-free model. So, instead of converting input text into a sequence of tokens, we can work directly with raw bytes. Working on raw bytes requires a very long context window and brings some benefits. Many Transformers use sub-word tokenization, which leads to biases but improves efficiency. Sub-word tokenization is having problems with out-of-vocabulary words, typos, spelling, capitalization, etc. MambaByte is an example of a token-free S4 model.
With the release of Mamba and Jamba, all of the current trends continue to drive progress in the LLM domain:
Hybrid architectures. MoE and mix of different layers in one model (Mamba and Transformer Layers together
Bigger models. Scaling is everything: hardware-aware optimizations, reduced algorithmic complexity, and removal of sequential operations.
Divide and conquer. For example, solving problems by finding specialized solutions - CNN and RNN modes.
Resources:
https://huggingface.co/blog/lbourdois/get-on-the-ssm-train - Introduction to State Space Models (SSM)
https://arxiv.org/abs/2312.00752 - Mamba: Linear-Time Sequence Modeling with Selective State Spaces
https://arxiv.org/abs/2403.19887 - Jamba: A Hybrid Transformer-Mamba Language Model
https://jackcook.com/2024/02/23/mamba.html - Mamba: The Easy Way
https://srush.github.io/annotated-mamba/hard.html - Mamba: The Hard Way
https://www.isattentionallyouneed.com/ - Is Attention All You Need?
https://jameschen.io/jekyll/update/2024/02/12/mamba.html - Mamba No. 5 (A Little Bit Of...)
https://srush.github.io/annotated-s4/ - The Annotated S4
https://arxiv.org/abs/2401.04081 - MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts
https://arxiv.org/abs/2401.13660 - MambaByte: Token-free Selective State Space Model
https://shchegrikovich.substack.com/p/rnn-vs-transformers-or-how-scalability - RNN vs Transformers or how scalability made possible Generative AI?
https://shchegrikovich.substack.com/p/mixture-of-experts-the-magic-behind - Mixture of Experts. The magic behind Mixtral models