
Low-level optimisations in Attention or why some LLM apps work faster than others

The attention mechanism makes LLMs so good at answering user's questions. It helps LLMs to find related words in a sentence. By calculating attention scores for each word, LLMs understand nuances. Logically, attention is made up of three vectors: query, keys, and values. Mathematically, we use the softmax operation to compute the score. These vectors are used every time we need to generate a new token.
The first optimization technique is to introduce a KV cache. Instead of recomputing keys and values for each token every time we see it, we can do it once and re-use it. Even with this optimization, the KV cache can be responsible for 30% of GPU memory. The PagedAttention paper took this idea even further by creating a scheduler for the KV cache. The job of a scheduler is to divide the KV cache into blocks. Instead of operating one big KV cache for one request, PagedAttention allows us to re-use blocks across requests by managing smaller blocks for a fixed number of tokens.

vLLM is an inference engine for LLMs built on top of PagedAttention and capable of serving modern LLMs such as LLaMa. Throughput improvements are 2-4x. vLLM has almost zero waste in KV cache memory.

But all of these would not be possible without an understanding of modern hardware. PagedAttention introduced a new way of working with memory, and to support it, the team developed new GPU kernels. Some people call this Mechanical Sympathy. "Mechanical sympathy is when you use a tool or system with an understanding of how it operates best.". Another example of Mechanical Sympathy is FlashAttention, which requires special hardware(NVIDIA A100, H100) and can be used with LLaMa, Phi-3, Mistral and 39 other architectures.
FlashAttention is an IO-aware algorithm that reduces memory operation between HBM and SRAM. HBM (high-bandwidth memory) is a memory stack located on the same physical package as the GPU and delivers over 3 TB/sec of memory bandwidth, but this is still 10x less than on-chip SRAM. As a result FlashAttention is 7.6X faster.

FlashAttention uses three technics: tilling, recomputation and online softmax trick. Tilling - instead of working on the whole big matrix, we divide it into tiles. This is why we can use SRAM, which is much smaller in size compared to HBM. Recomputation replaces memory access operations with calculations. Instead of retrieving results from memory sometimes, it's faster to do a calculation once again. The last piece is to compute the softmax for each tile instead of the whole matrix at once. In FlashAttention-2, the focus was on reducing non-matmul operations and a further improvement in memory access, which led to another 2-3x speedup.
If PagedAttention is focused on improving memory efficiency via reducing memory waste, FlashAttention reduces IO operations by doing everything using on-chip memory. However, both of them use NVIDIA's advantages. Apart from big memory and fast matrix operations, NVIDIA provides a specific module for LLMs—Transformer Engine. This engine dynamically chooses which precision to use for Transformer layers. Basically, it uses statistics and converts from FP8 and 16-bit calculations before storing them in memory. 9x in AI training and 30x during inference are guaranteed.

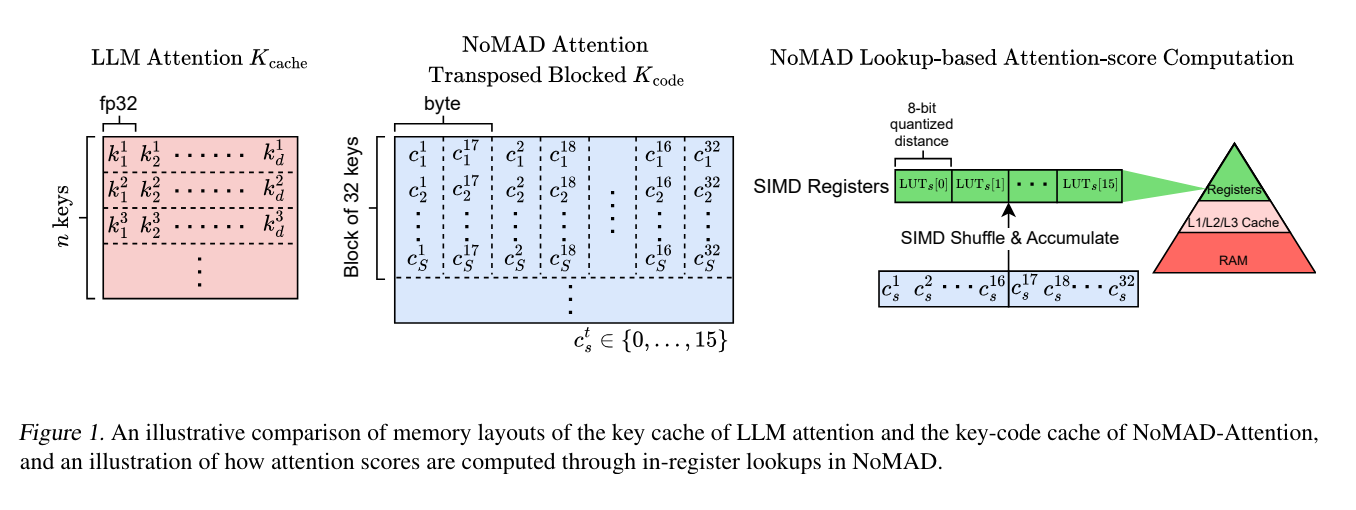
An alternative to this is inference on CPU. The main blocker here is multiple MAD operations. Multiply-add (MAD) matrix operations are often used in Attention computation. If MAD is where GPUs are good, SIMD (Single Instruction Multiple Data) is where CPUs are good too. The NoMAD paper proposed this - let's use SIMD registers in the CPU to replace expensive MAD operations with ultra-low latency in-register lookups. The results are interesting - 4-bit quantized LLaMa-7B can work 2x faster.
References:
https://wa.aws.amazon.com/wellarchitected/2020-07-02T19-33-23/wat.concept.mechanical-sympathy.en.html - Mechanical Sympathy
https://arxiv.org/abs/1706.03762 - Attention Is All You Need
https://arxiv.org/abs/2309.06180 - Efficient Memory Management for Large Language Model Serving with PagedAttention
https://arxiv.org/abs/2205.14135 - FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
https://arxiv.org/abs/2307.08691 - FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
https://arxiv.org/abs/2405.02803 - Is Flash Attention Stable?
https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/ - NVIDIA Hopper Architecture In-Depth
https://resources.nvidia.com/en-us-tensor-core/gtc22-whitepaper-hopper - NVIDIA H100 Tensor Core GPU Architecture
https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one - GPU inference
https://arxiv.org/abs/2403.01273 - NoMAD-Attention: Efficient LLM Inference on CPUs Through Multiply-add-free Attention
https://en.wikipedia.org/wiki/High_Bandwidth_Memory - High Bandwidth Memory