


Large reasoning models meet RAG

Large reasoning models (LRMs) have shown great performance at solving complex reasoning tasks. Traditional LLMs are scaled by increasing model size and training on growing data. Large reasoning models are scaled at test time by increasing reasoning steps. What happens if we combine LRMs with RAG?
The "Search-o1: Agentic Search-Enhanced Large Reasoning Models" paper explores the idea of combining RAGs and LRMs. The main goal here is to extend the knowledge available for the model during reasoning. Without external knowledge, the model might start suffering knowledge in-sufficiency, which leads to uncertainties and errors. These issues can be found by calculating uncertain words(wait, likely, alternatively and etc) in responses.

The core of the Search-o1 framework is an Agentic RAG and a knowledge refinement module. The goal is to integrate a search workflow into the reasoning process, which will add external knowledge to specific steps of the reasoning process. The Agentic RAG module dynamically triggers search queries and adds new information. The knowledge refinement module or Reason-in-Documents module is responsible for efficiently producing summaries of external documents. It removes redundant information and understands long documents by producing refined information to integrate into the reasoning process.
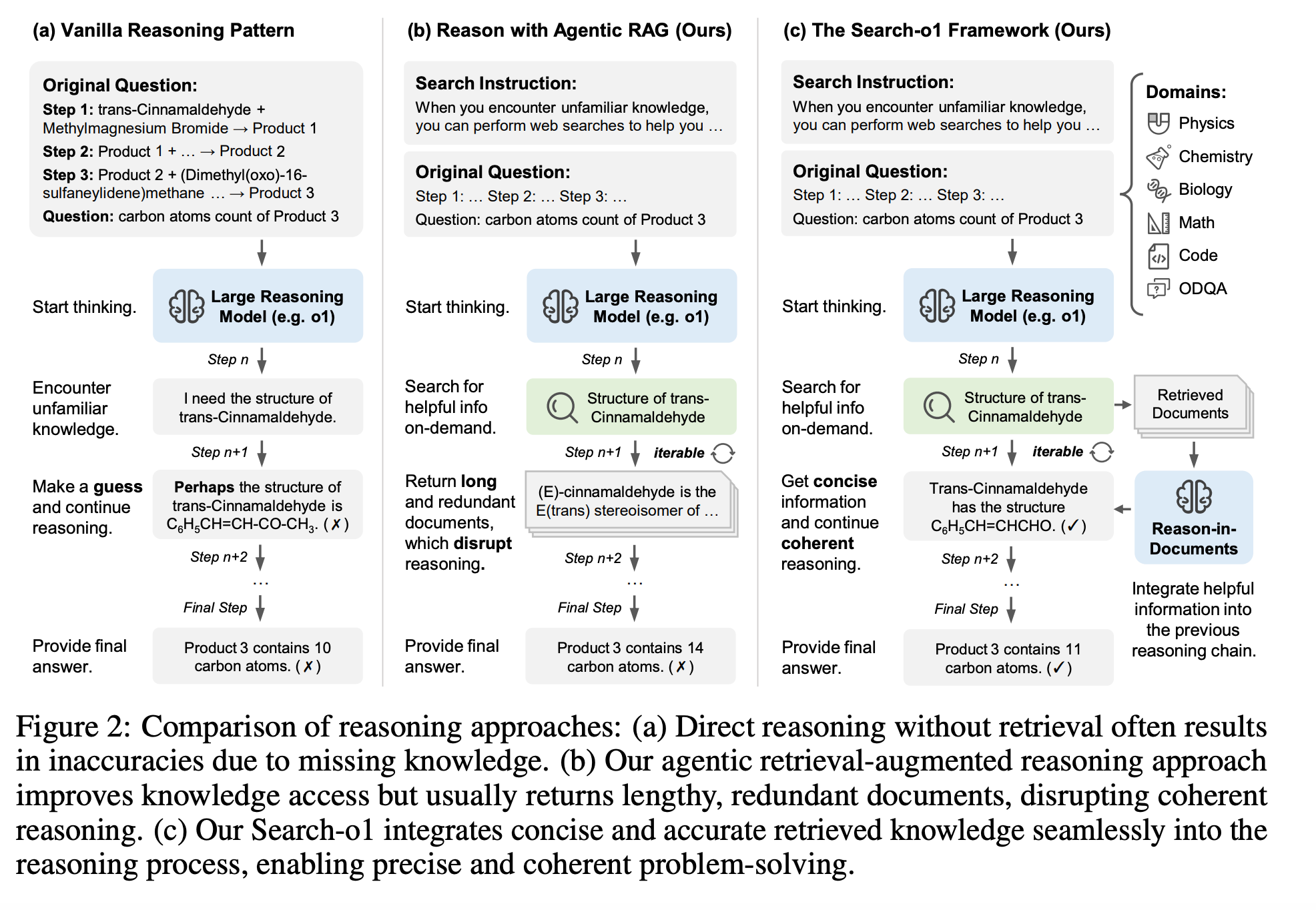
From an implementation perspective, the Search-o1 generates special symbols to trigger an external search - <|begin_search_query|>. Also, the search is executed in parallel using the branch inference mechanism to speed up the reasoning process. This mechanism creates batches from search queries to do document retrieval and refinement.

The CoRAG paper focuses on dynamically reformulating the query based on the current reasoning state. CoRAG proposes a method for generating retrieval chains. Each chain consists of sub-queries and sub-answers. Retrieval chains use RAG to find external documents. The first step is to fine-tune the model to create such chains. Model training has three tasks: next sub-query prediction, sub-answer prediction and final answer prediction. Once the model is ready, we can use different test-time strategies (greedy decoding or tree search) to control the trade-off between performance and compute time.

References:
Paper: Search-o1: Agentic Search-Enhanced Large Reasoning Models - https://arxiv.org/abs/2501.05366
Paper: Chain-of-Retrieval Augmented Generation - https://arxiv.org/abs/2501.14342v1