


Language Models Meet Diffusion

Auto-aggressive models dominate the LLM space. Their most distinctive feature is to generate output one word at a time. It means that to create an output of 5 words, the model needs to make five passes, using all previously generated tokens and the prompt. This is not cheap in terms of time and computational resources required. Another problem is that the model has no way to review an output before sending it back to the user. One incorrectly generated token can completely ruin the answer.
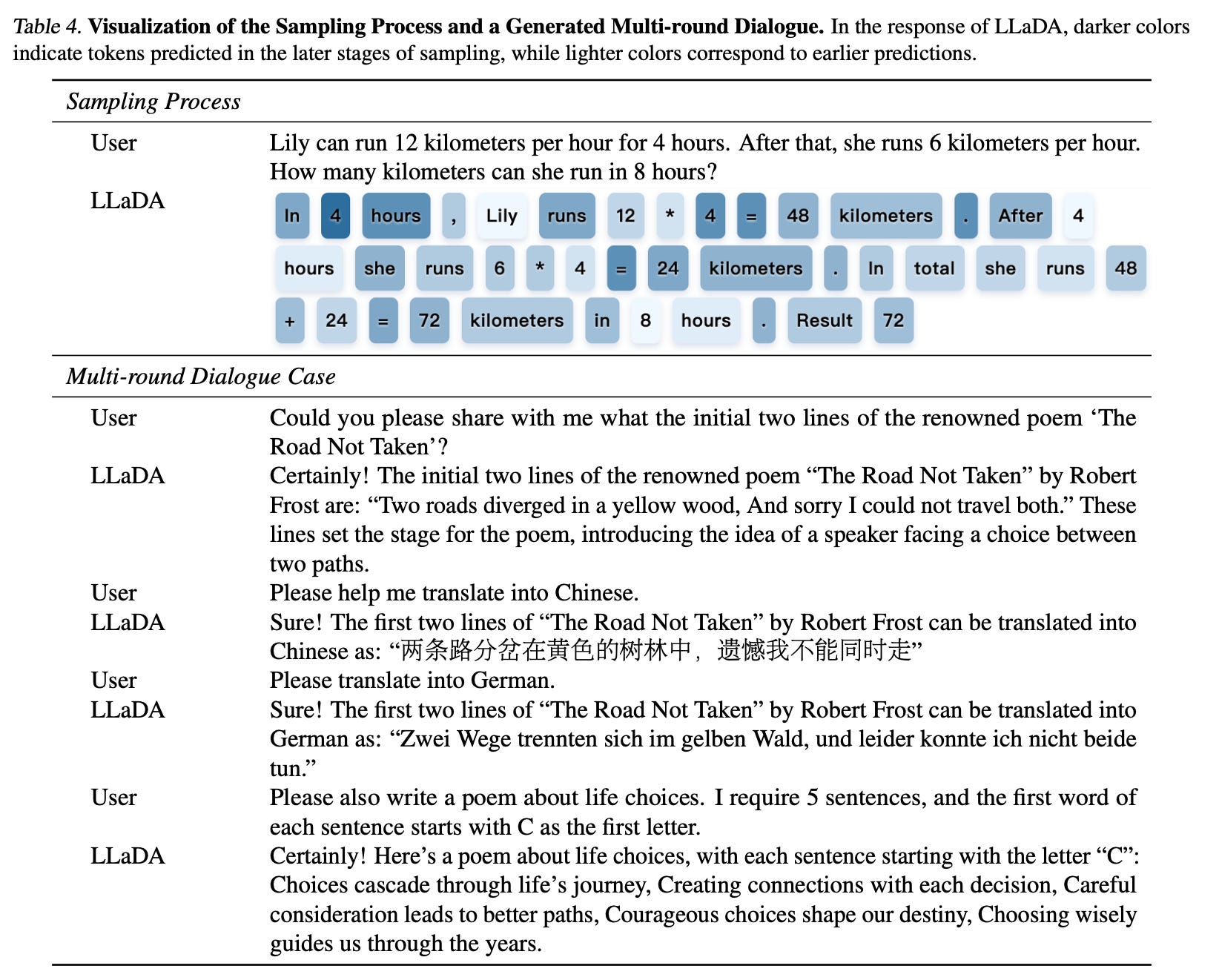
The answer to these problems might be Diffusion Models. In the LLaDA(Large Language Diffusion Model with Masking) paper, a new architecture is proposed. Diffusion Models are super popular in image generation, and now it's time to apply the same principles in Language Models. In the LLM world, it means generating several output tokens simultaneously.

The LLaDA proposes changes in the Pre-Training, SFT, and Inference stages. During the Pre-Training stage, LLMs are taught to guess the next word. It's done by hiding the last word in a current test data chunk from the model. In the LLaDA, we hide not exactly the last word, but randomly several words at different positions. During the SFT, we hide words in the response part only. The main difference is in the Inference stage. The Inference stage in the LLaDA is split into steps. At each step, the model generates several tokens at different positions. The process stops when all tokens are generated. Basically, compared to the auto-aggressive architecture, we have additional hyperparameters for response length, number of steps, and number of generated tokens per step. The LLaDA architecture allows for re-masking, which means we can re-generate tokens that do not look right. This inference process mimics how humans review internal thoughts before making a final decision.
As a nice side effect of the new architecture is an improved result on the Reversal Curse tests. The Reversal Curse manifest itself in an inability to make reversible factual associations. In other words, if the 4th of July is the USA Independence Day, then Independence Day is on the 4th of July. It sounds like a simple task, but for LLM, it requires making basic generalisations. The first version of Llama was accurate only in 7% of cases in the Reversal Curse test. The LLaDA 8B beats GPT-4o by 8 points in the Reversal tests - 42.4%.

Since June of this year, Diffusion Language Models(dLLMs) are not just a theoretical thing. InceptionLabs gave access to their family of Mercury models. These models are super fast and focused on software development tasks.

Resources:
Paper: The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A" - https://arxiv.org/abs/2309.12288
Paper: Large Language Diffusion Models - https://arxiv.org/abs/2502.09992
Paper: Mercury: Ultra-Fast Language Models Based on Diffusion - https://arxiv.org/abs/2506.17298