


Improved planning for AI Agents

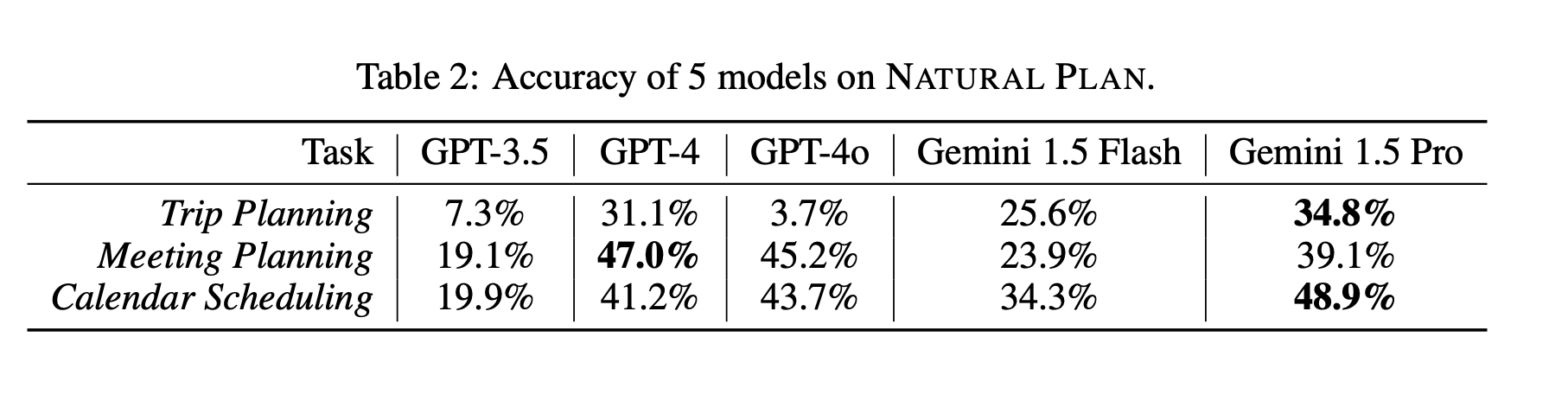
In June 2024, Google DeepMind released an interesting benchmark, Natural Plan. The idea was to understand LLM's capabilities in planning for real-world scenarios. The benchmark consists of three types of tasks: trip planning, meeting planning and calendar scheduling. The best models at that time had an accuracy of less than 50%. A trip planning task with 10 cities(high solution depth) was almost impossible to solve - all models fell below 5%.
The reason why planning is so hard can be seen in the comparison of myopic and planning problems. Myopic problems can be solved with simple reasoning and memorisation without a need for a long-term strategy. We can apply this approach by prompting an agent 'Always respond with humour.' This might work quite well until the agent is tasked with a sensitive topic. Planning problems, on the other hand, require creating a multi-step plan that considers future states and revises the plan based on intermediate results. Incorporating self-doubt and verification, heuristic reasoning, backtracking, and state tracking is almost always necessary for planning problems.
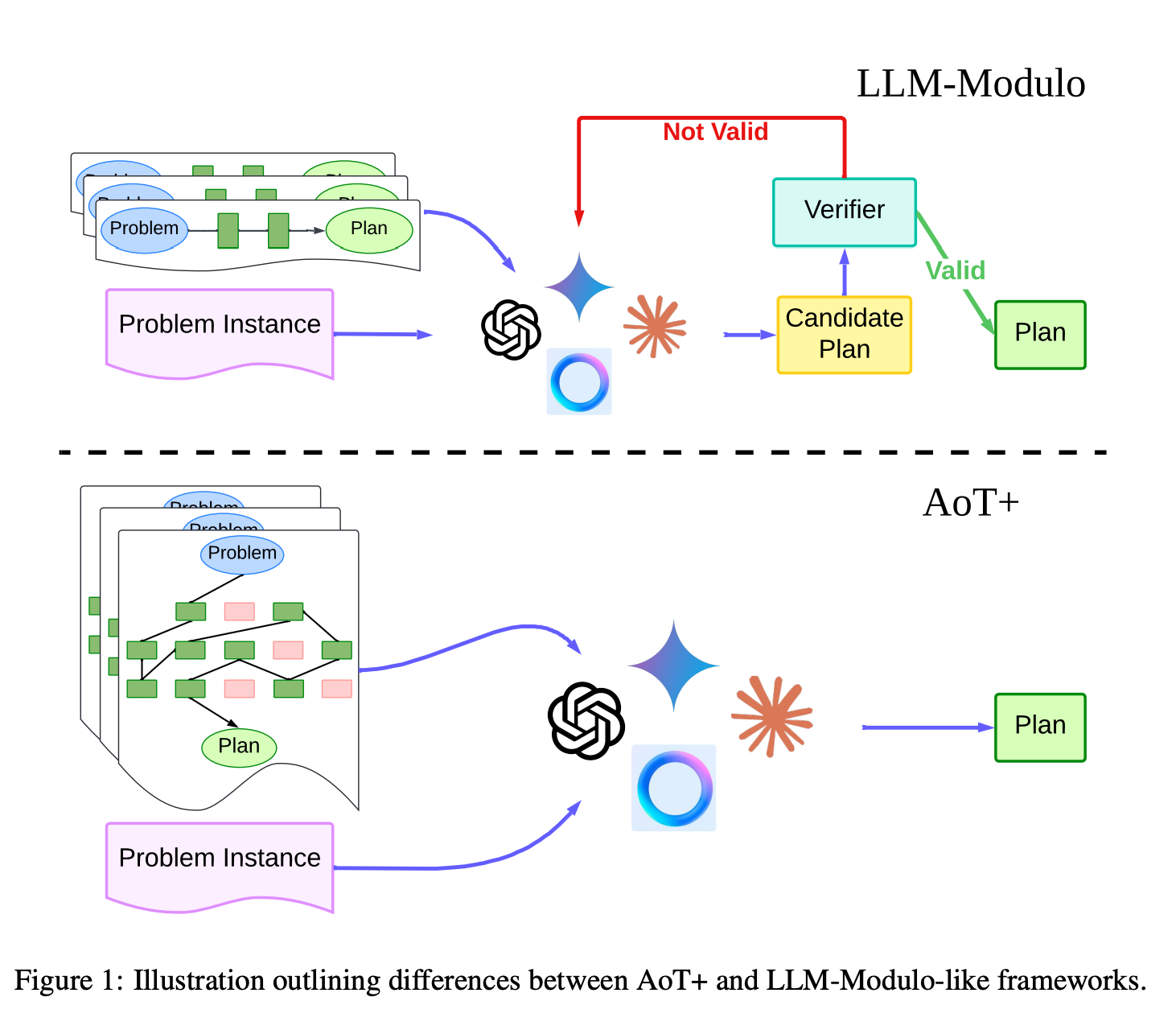
The AoT+ paper presents an interesting approach that not only improves planning accuracy but also maintains a lower error rate for higher solution depth. In the AoT, a prompt was constructed by adding backtracking examples(in-context examples for backtracking in case of a dead-end solution). AoT+ extends the prompt with a mix of successful and failed plan examples. Also, AoT+ incorporates memoisation - periodically restating the full state after each planning step with hierarchical labels for tagging different branches. Memoisation is a key approach in combating the forgetting of previous states and reducing the error rate for higher solution depths.
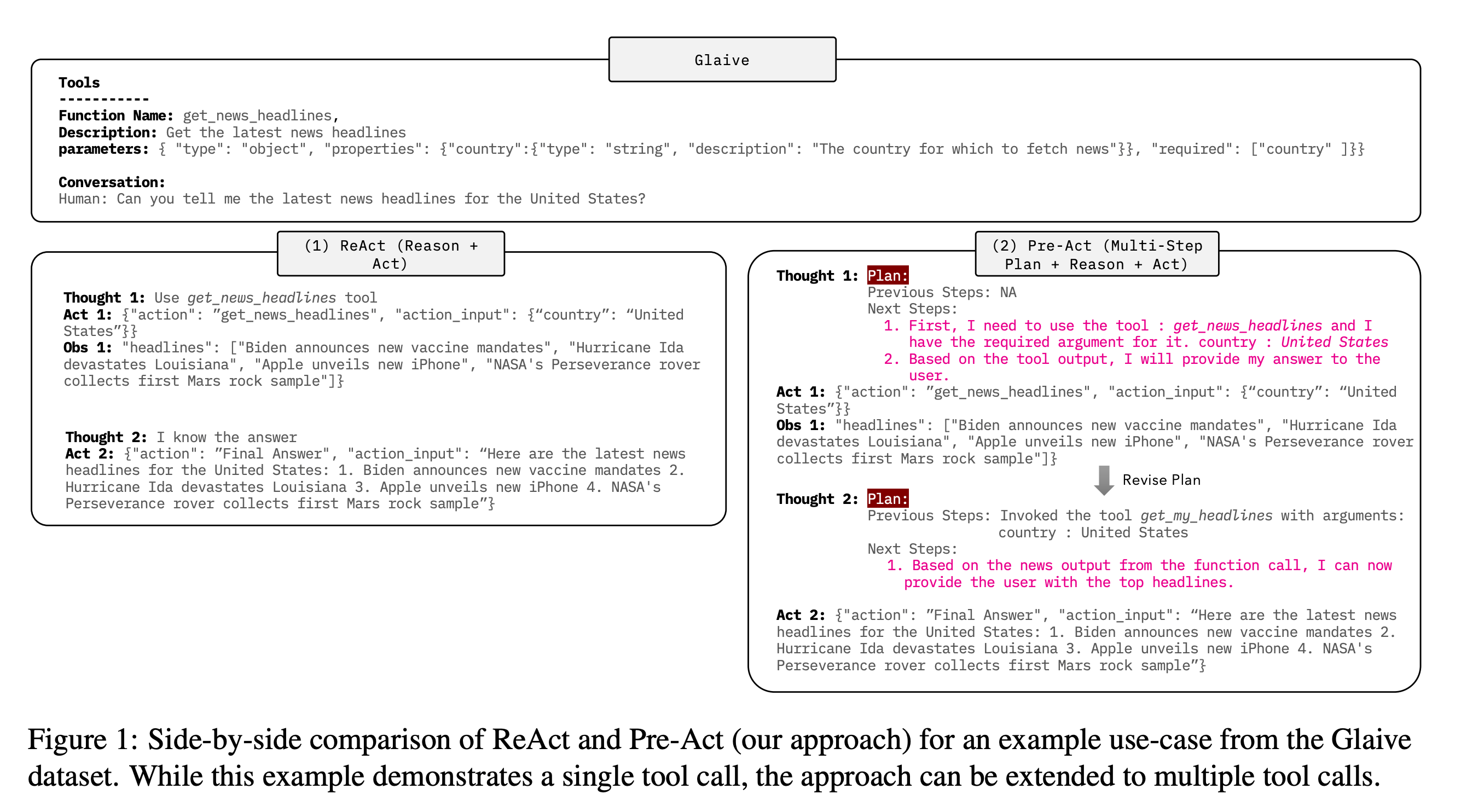
The Pre-Act paper presents an enhanced version of ReAct, incorporating additional planning and refinement steps. The execution loop starts from initial planning(generates a blueprint plan based on input and available tools). The next step is to execute the proposed tool. The tool result is added to the context, and the refinement step is called to decide on the next tool to call or return the result. What we see here is some variation of in-context learning with a successful trajectory. It's been added to improve global planning and better handle multi-step tasks.
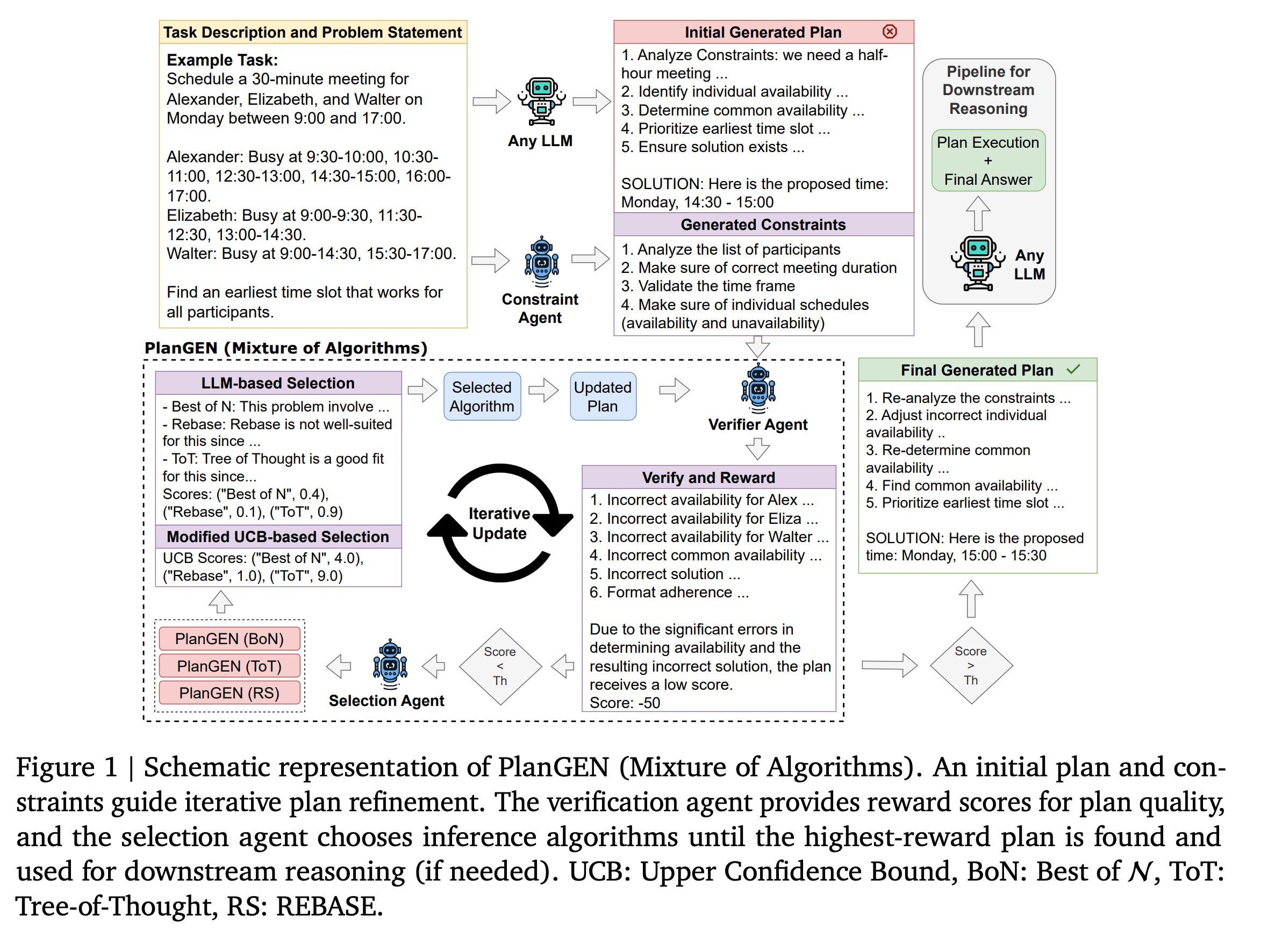
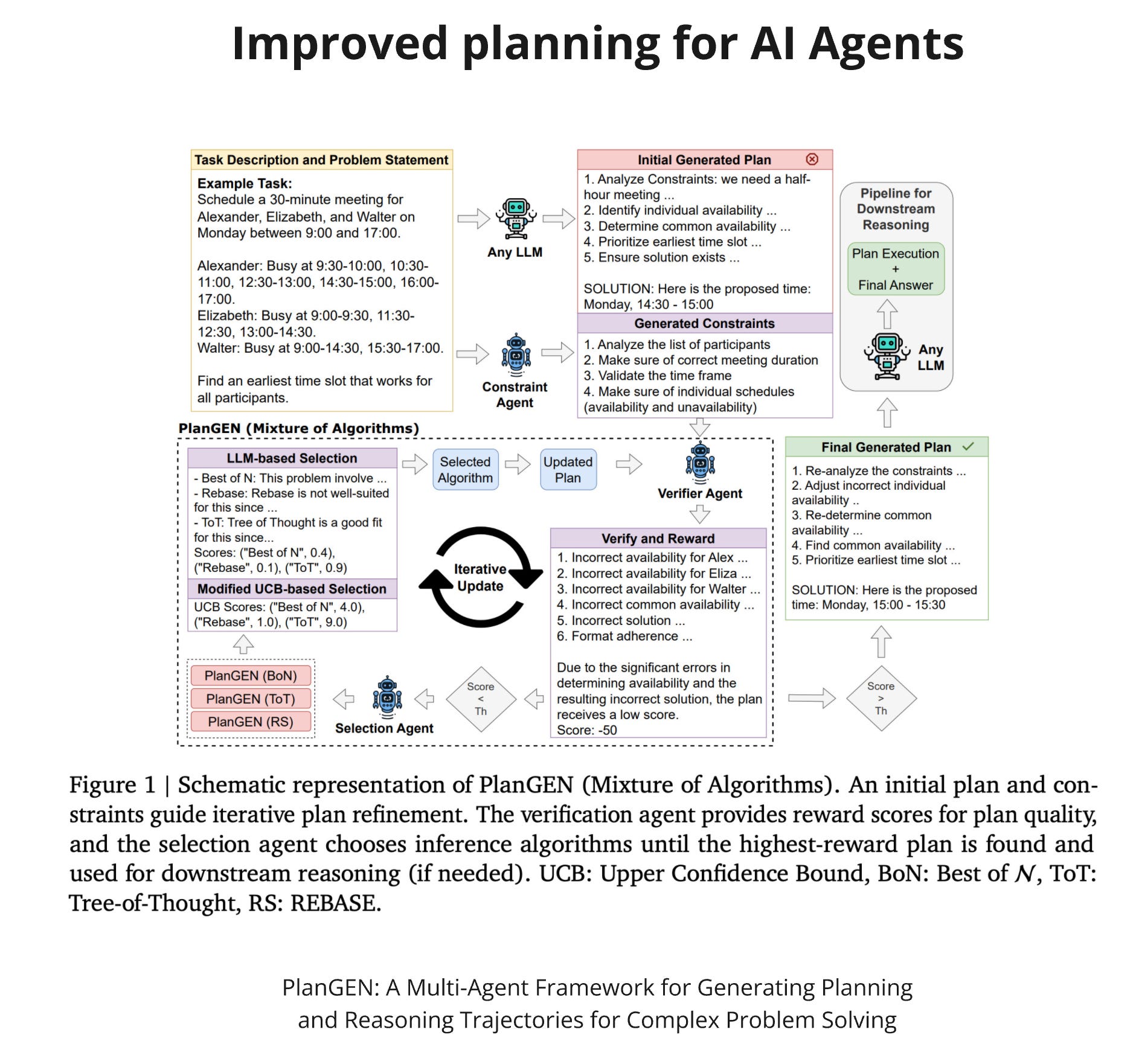
An agent-based approach was proposed in the PlanGEN paper from Google. The idea is to build three agents: constraint agent, verification agent and selection agent. The agents work together toward an accepted plan. Verifier provides scoring for generated plans. A plan is accepted only if its score is above the threshold. It's the task of the selection agent to choose the best approach to improve the plan. The constraint agent is used at the beginning to extract constraints from the user's task. On the Natural Plan, this approach achieves an accuracy of 60.70.
Resources:
Paper: NATURAL PLAN: Benchmarking LLMs on Natural Language Planning - https://arxiv.org/abs/2406.04520
Paper: Automating Thought of Search: A Journey Towards Soundness and Completeness - https://arxiv.org/abs/2408.11326
Paper: LLMs Can Plan Only If We Tell Them - https://arxiv.org/abs/2501.13545
Paper: PlanGEN: A Multi-Agent Framework for Generating Planning and Reasoning Trajectories for Complex Problem Solving - https://arxiv.org/abs/2502.16111
Paper: Pre-Act: Multi-Step Planning and Reasoning Improves Acting in LLM Agents - https://arxiv.org/abs/2505.09970