
How to use LLM-judge?

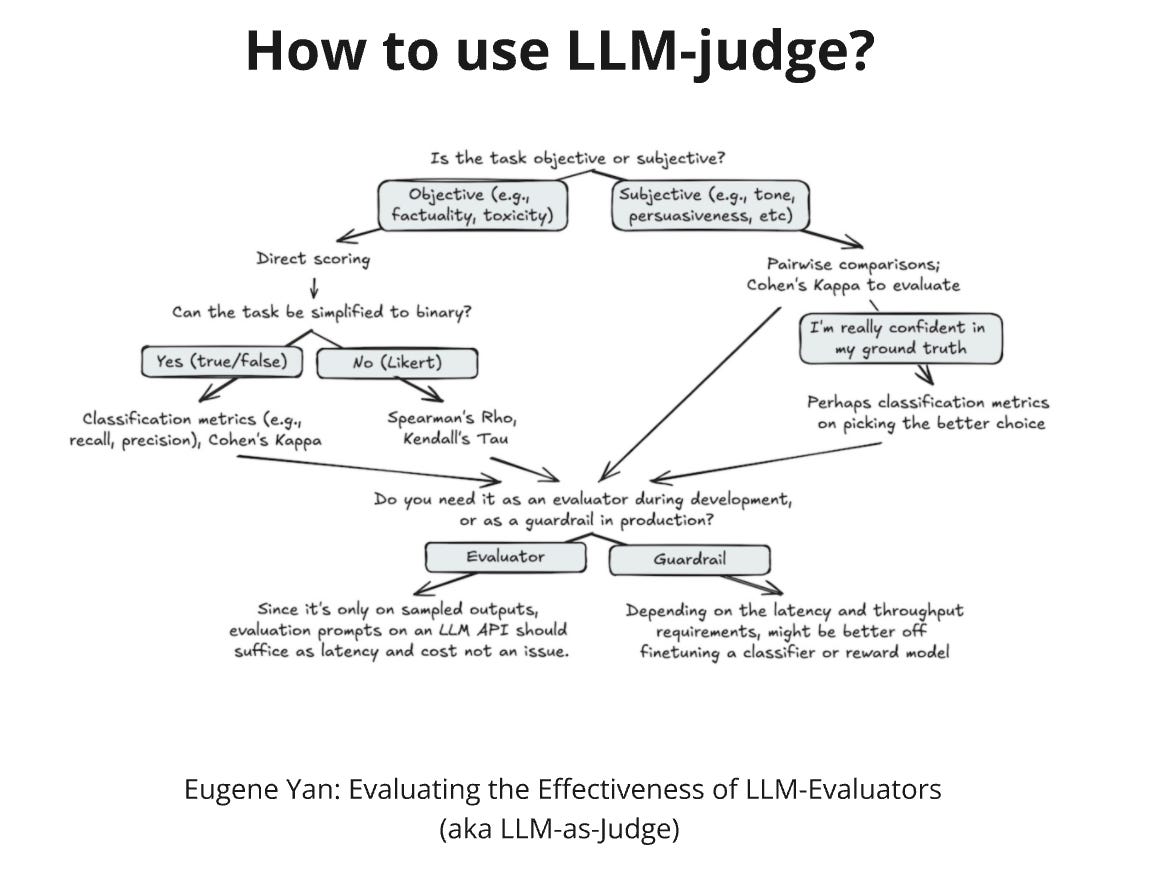
LLM-judge is one of the techniques to estimate how well your LLM app works. For instance, you have two versions of the summarization prompt. It's quite hard to measure a summary and say which version works better. The best way is to send the summary to a few people and ask for feedback, but what if you don't have access to a test group or need to check the quality of hundreds of prompts? In this case, the cheaper option is to use LLM-judge.
'Review this code and find things that should be improved' is a simple LLM-judge prompt developers can use daily at work. It's believed that LLMs can review the code as fellow developers in this example. This belief is based on the fact that human preference data were used during training. So, if LLMs were trained to predict what people would like, then we can use LLMs to judge other prompts.
To prove this, we can calculate how well LLMs mimic human judgment. This is done by calculating correlation metrics, such as Cohen's kappa coefficient. This coefficient can take values from -1 to 1, where 1 means a perfect agreement. In some tests, GPT-4 achieves Cohen's coefficient of 0.84 for human alignment. The range from 0.81 to 1 means almost perfect alignment. Humans show an alignment of 0.97 in tests. Llama-3-70B falls slightly behind with 0.79, which means a substantial agreement.
There are three ways LLM-judge can be used: pairwise comparison, single answer grading(scoring), or reference-guided grading. In the first case, pairwise comparison, we show LLM two results we want to compare and ask which one is better. Scoring, here, we show only one example and ask for a score from 0 to 5. In the last case, reference-guided grading, we provide a reference example and ask LLM to choose the best answer.
There is one problem with applying the LLM judge technique: biases. LLMs show position and length biases and prefer content generated by LLM itself. This means that a long answer generated by LLM in the first position will have a better chance of winning. To reduce biases, a set of rules was developed:
Use several models
Randomize position
Provide a few examples specifically for scoring.
LLM-judge doesn't replace a golden standard - human evaluation but makes the whole process faster and cheaper.
Resources:

https://eugeneyan.com/writing/llm-evaluators/ - Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge)
https://arxiv.org/abs/2408.13006 - Systematic Evaluation of LLM-as-a-Judge in LLM Alignment Tasks: Explainable Metrics and Diverse Prompt Templates
https://arxiv.org/abs/2408.11729 - LLM4VV: Exploring LLM-as-a-Judge for Validation and Verification Testsuites
https://arxiv.org/abs/2408.10718 - CodeJudge-Eval: Can Large Language Models be Good Judges in Code Understanding?
https://arxiv.org/abs/2306.05685 - Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena