
Evaluating Conversational AI Agents

Evaluation of prompts in the LLM world is hard; evaluation of conversational agents is even harder. One problem is defining clear success metrics. For multi-turn conversations, it can be particularly challenging. Additionally, in chats, we also have tools that significantly increase complexity. Luckily for us, there are ways to do the evaluation.
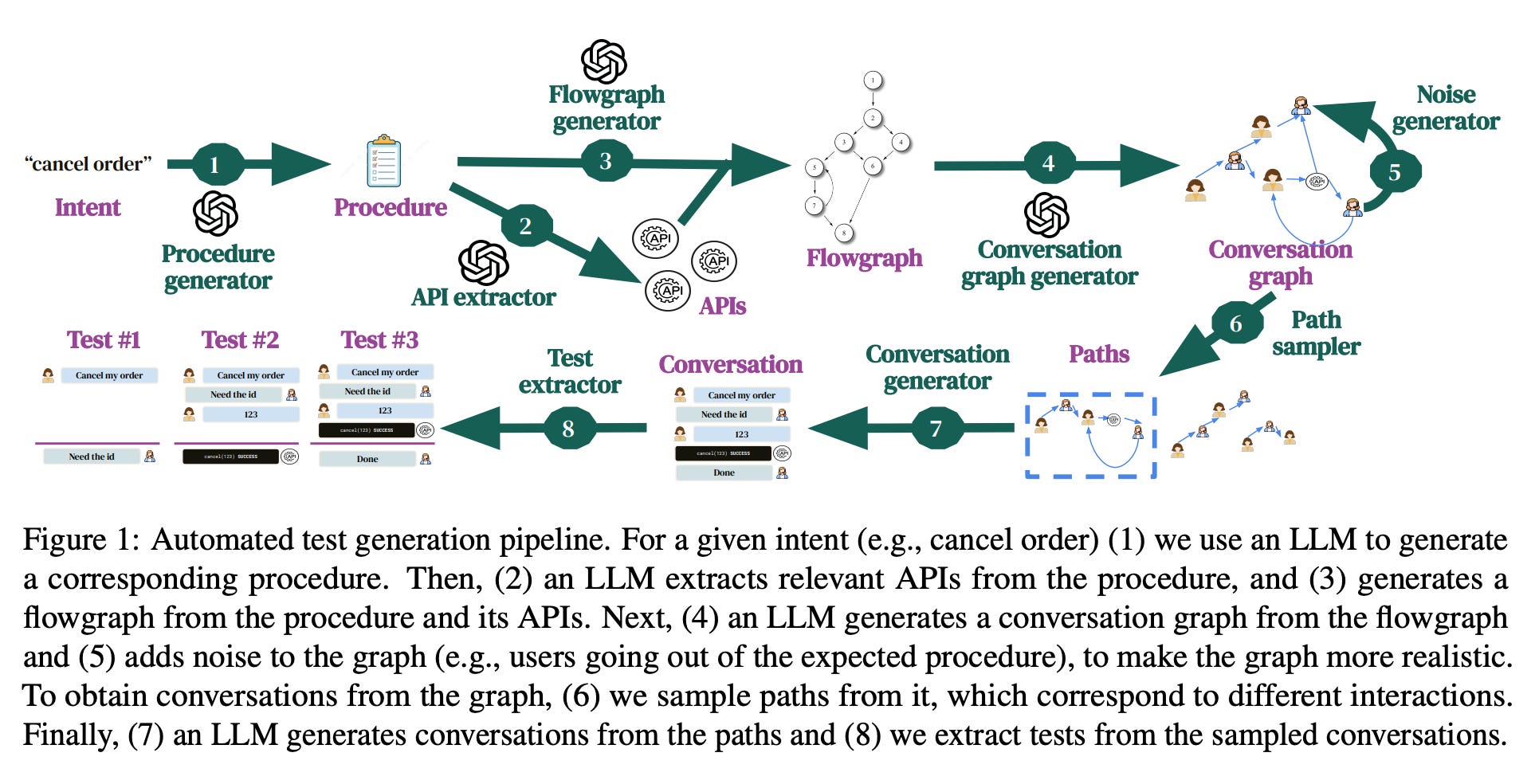
The paper from ZenDesk proposes a solution for support systems. The idea is to generate evaluation tests automatically. Once the tests are ready, we can run them against an agent and measure its effectiveness. The result of the evaluation is the conversation correctness metric, which shows whether all tests in a particular conversation are correct. The paper considers a test successful when all API calls and replies are correct.
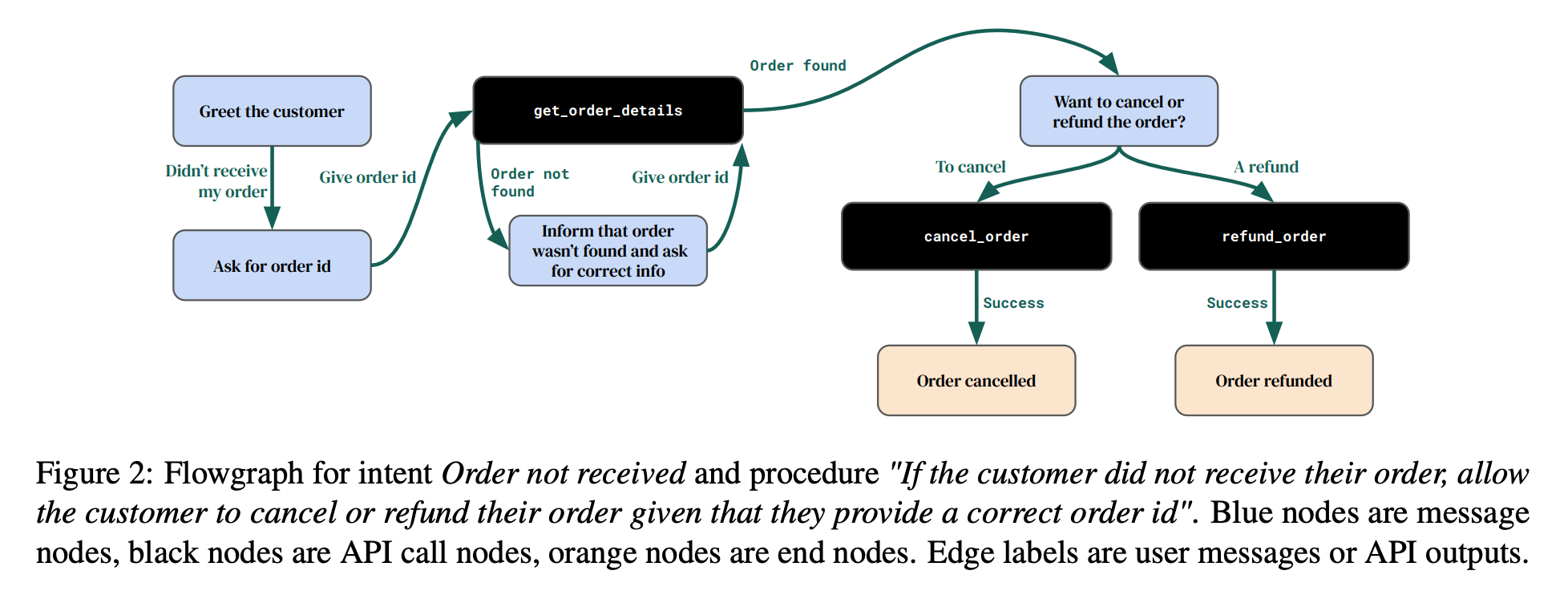
The core component is the test generation pipeline for a support system. The pipeline begins with intent generation (cancelling an order or refund request), based on which a procedure is generated. A procedure is an unambiguous, API-based, step-by-step plan of what the system must do to resolve the intent. The next step extracts API calls, including names, parameters, and expected response types. Once API calls are extracted, a flowgraph is built. The flowgraph formalises the logic of agent execution. The flowgraph is used to construct the Conversation Graph, which represents a realistic conversation workflow with examples of user and agent responses. Now we have all the information to generate conversations and extract tests from them.
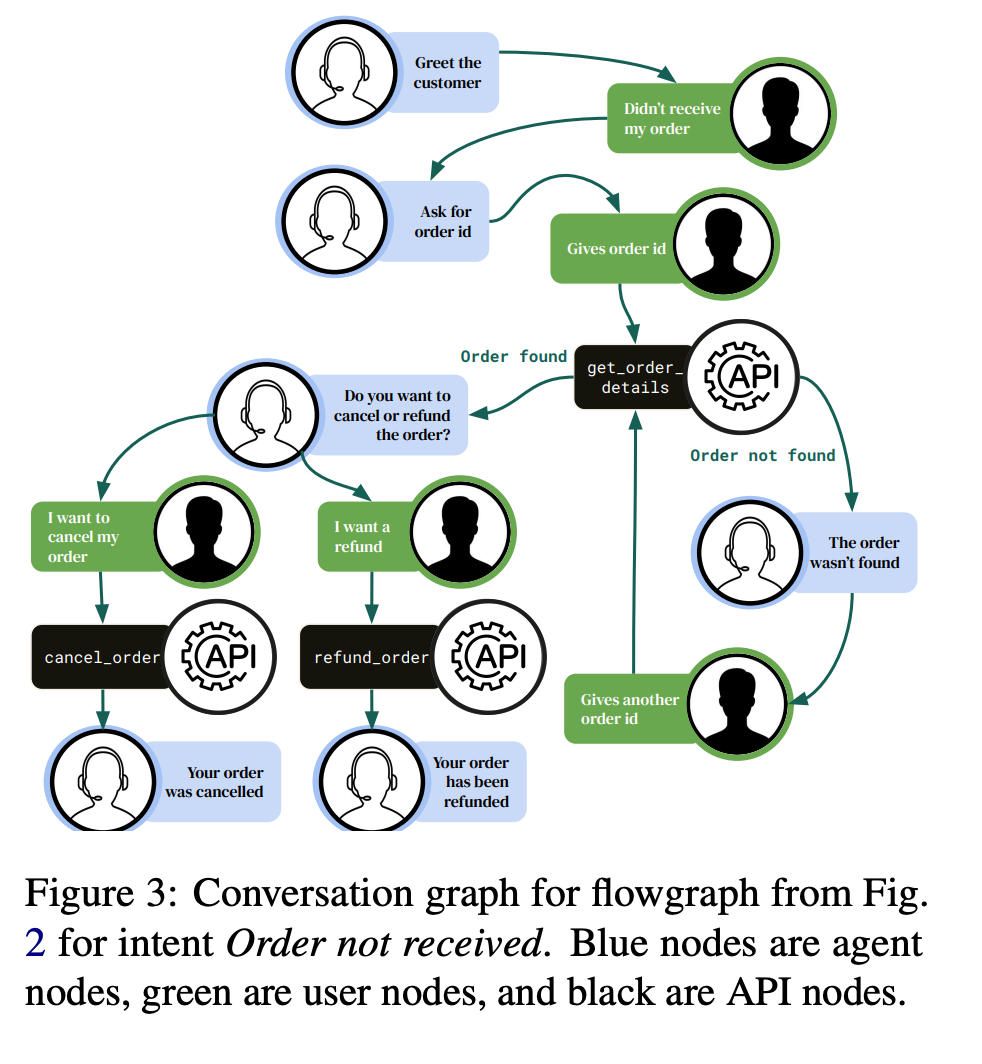
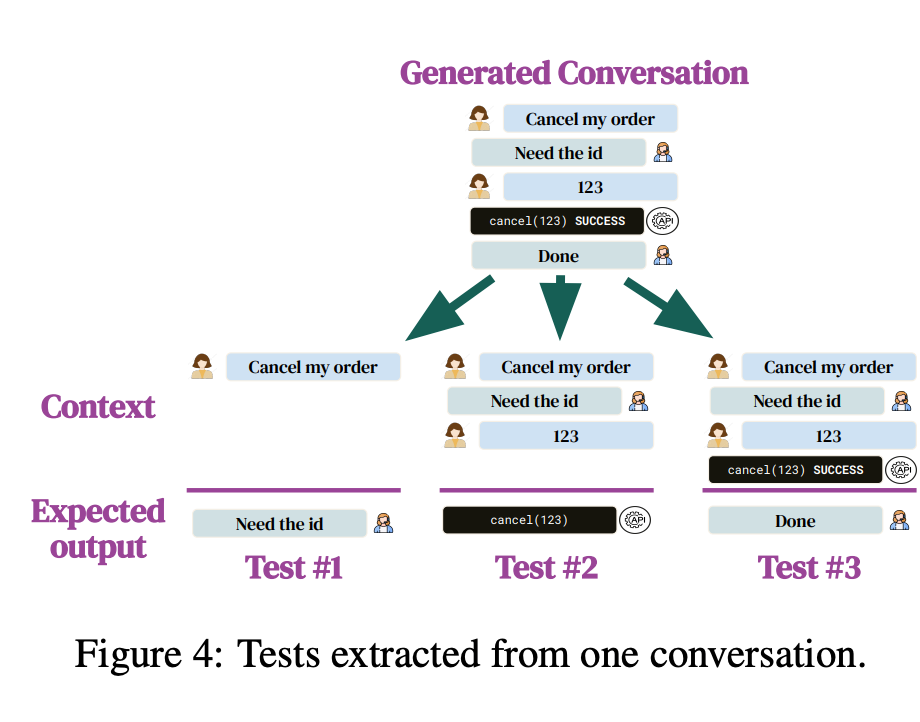
A conversation is a path from the Conversation Graph with a strict format: user -> assistant -> API call -> ... So, one Intention is converted into one Conversation Graph, which is used to generate multiple conversations, where one conversation is used to extract multiple tests. A test consists of context (messages from the user and/or the assistant) and expected output (a reply or an API call).
Besides evaluating agents on the expected execution flow (as above), we can also evaluate agents based on their skills(episodic memory, managing information conflicts, checking information integration, etc). The Beyond Prompts paper proposes several test scenarios (changing the name in the conversation, providing information about a favourite colour, and asking for jokes), which are tested during a normal conversation with an agent. In the previous paper, we ran tests in isolation; here, we use a continuous exchange of messages.
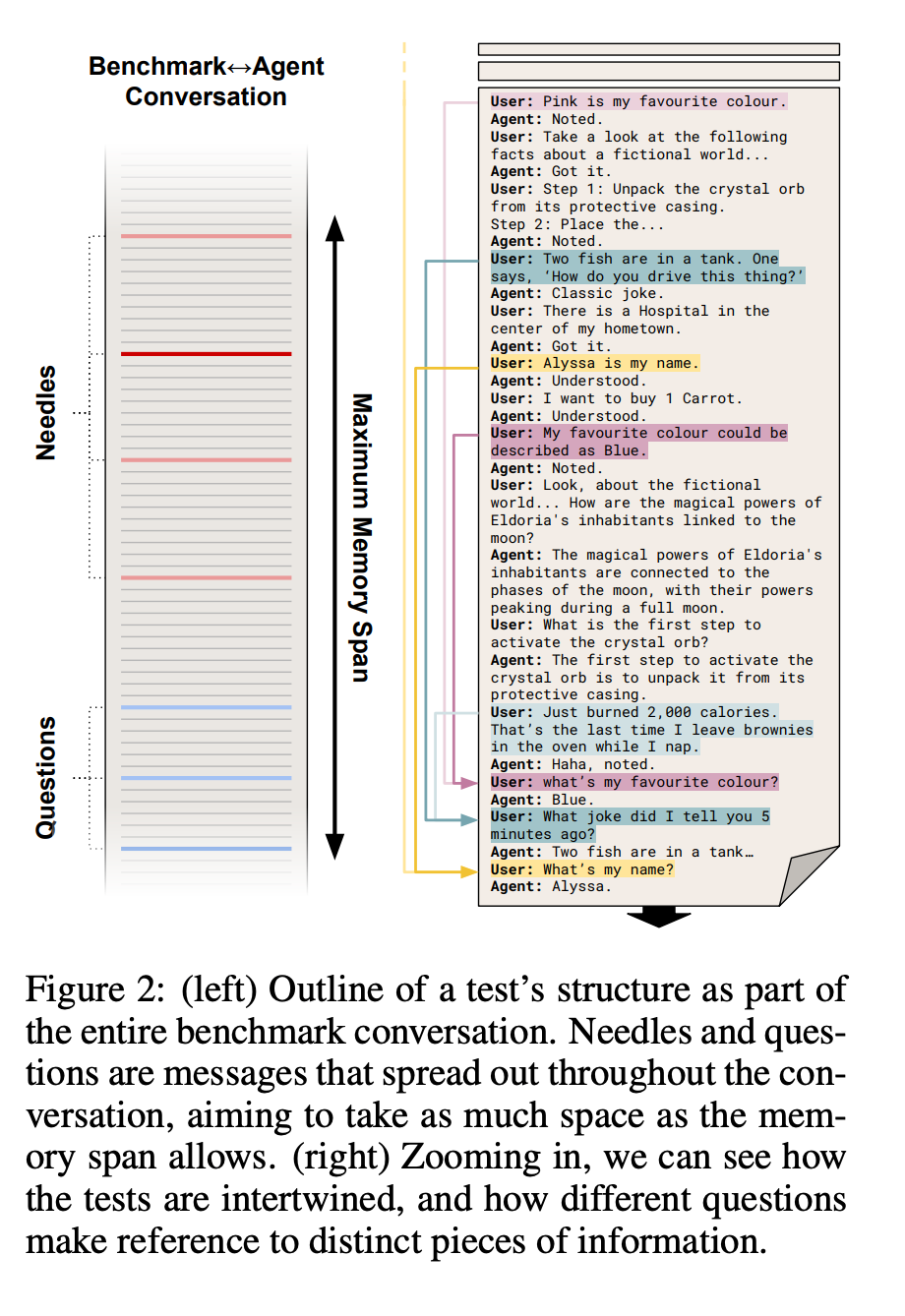
The scoring system is used to measure performance. The paper proposes using string matching and LLM-based evaluation to check agents' replies.

We can say that the ZenDesk approach is an example of grey-box testing - we know about API calls, we need to know about the purpose of an agent, but we do not know about the internal structure of the agent. The Beyond Prompts paper employs black-box testing - we know nothing about the agent, but we only care about its skills. The white-box approach is presented in the IntellAgent paper. The IntellAgent requires access to the system prompt of the agent or an internal document with domain-specific policies. Having access to the internals, the IntellAgent automates the creation of evaluation tests.
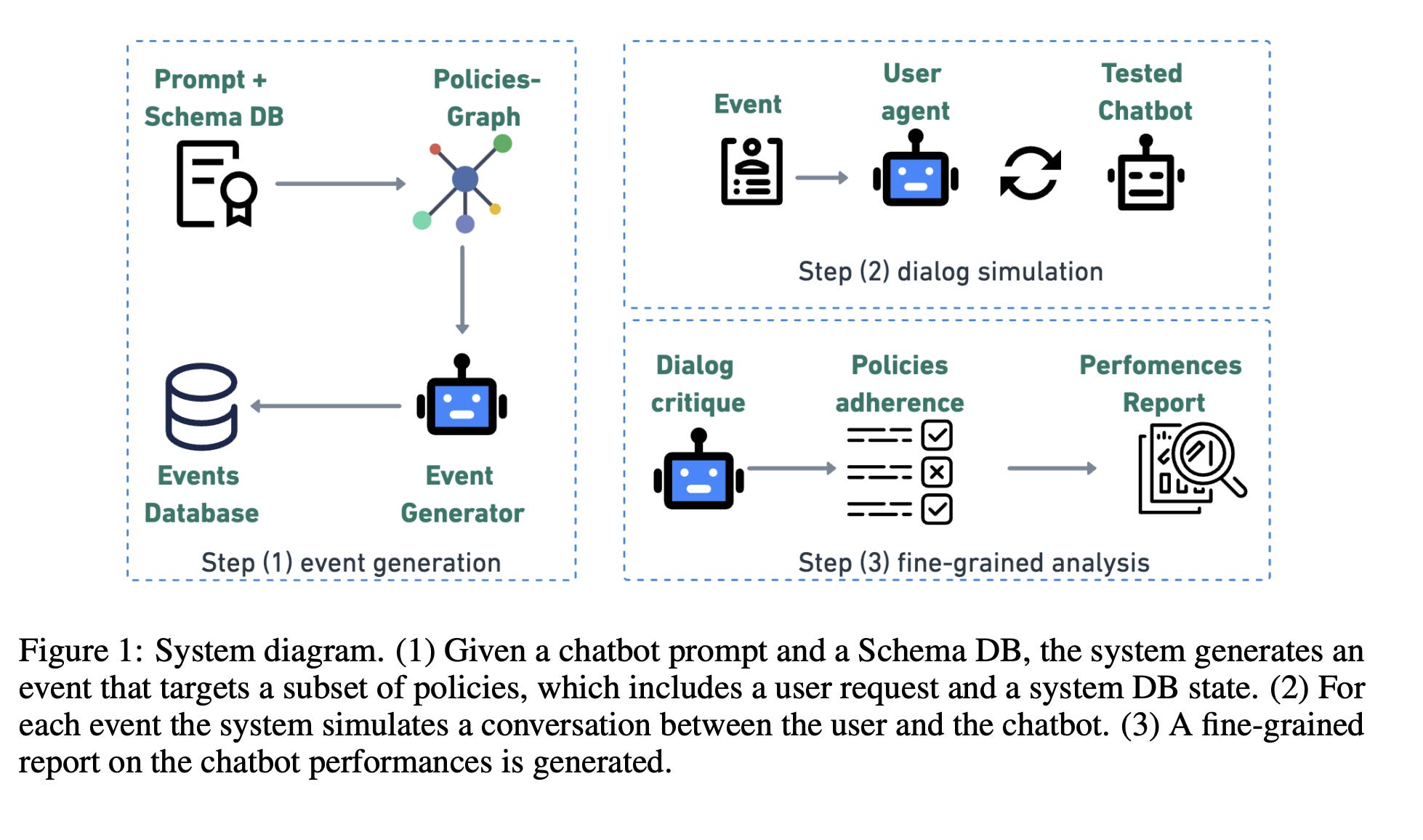
It starts from a policy graph based on the schema of a database(users, orders, items, etc) and the agent's system prompt. The resulting graph has nodes (individual policies - deny access to other users' data), edges (the possibility of policies to occur together), and weights (the difficulty of a policy for a sampling algorithm). The graph is used to generate events(randomly selected policies with target difficulty, user request for triggering policies and valid DB state). The test is a simulated conversation that checks for misbehaviour, completeness, and adherence to policies. The user agent simulates a conversation with the agent under test. The critique agent is used to measure the dialogue between agents.
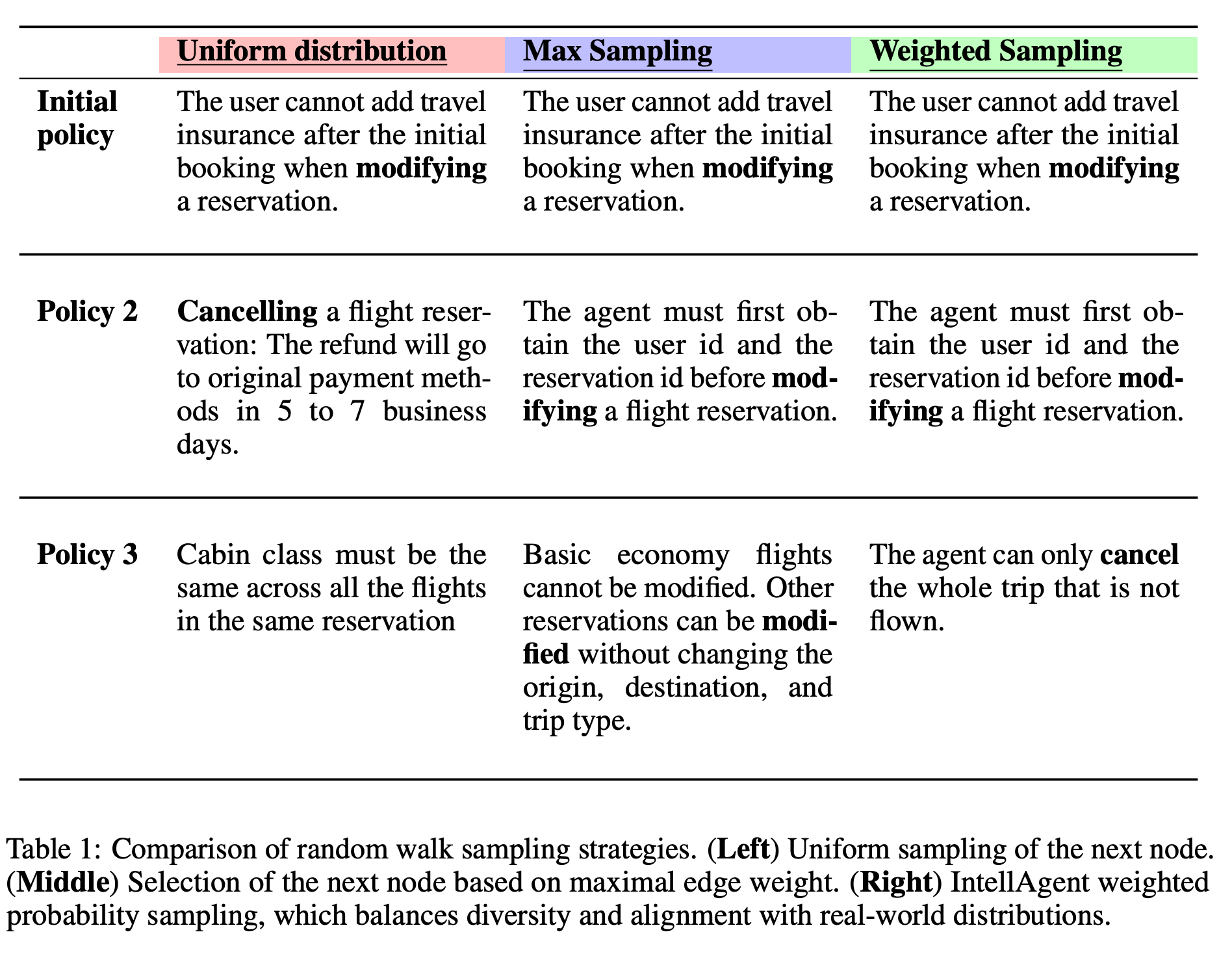
All of these papers take security seriously. They introduce specific prompt techniques (such as not asking the user for a password) or use irrelevant user requests in conversations to trigger misbehaviour of the agent. It is worth mentioning that such evaluation systems may be costly to run regularly, so developers need to consider using caches and more cost-effective models to test systems regularly. Another point to consider is a continuous development cycle. Developers constantly add new tools and policies, and these need to be integrated into the evaluation benchmark.
References:
Paper: Beyond Prompts: Dynamic Conversational Benchmarking of Large Language Models - https://arxiv.org/abs/2409.20222
Paper: IntellAgent: A Multi-Agent Framework for Evaluating Conversational AI Systems - https://arxiv.org/abs/2501.11067
Paper: Automated test generation to evaluate tool-augmented LLMs as conversational AI agents - https://arxiv.org/abs/2409.15934