
Creating an embedding model

Earlier this year, Google and NVidia shared papers on their new embedding models - Gecko and NV-Embed, respectively. If the Gecko paper only said that they use "a 1.2B parameter pre-trained transformer language model", NV-Embed, on the other side, used Mistral-7B.
The Gecko paper focuses on distilling knowledge from LLM into a dataset, which is later used to train the embedding model. The dataset preparation process involves two steps: generating data and extracting high-quality positive and negative pairs. The resulting dataset, FRet (Few-shot Prompted Retrieval), consists of tasks, queries, and positive and negative pairs.

FRet uses real web pages to generate synthetic data. It takes a passage from a web page and instructs LLM to generate tasks and queries. The main criterion here is to have good diversity. Once we have a set of tasks and queries for the web page, we need to extract the best passages from the original page for each pair. In the second step, extracted passages are ranked and classified by LLM to find the best positive and negative candidates. The paper proves that quality beats quantity; when the model was released, it was on par with 7x bigger models.
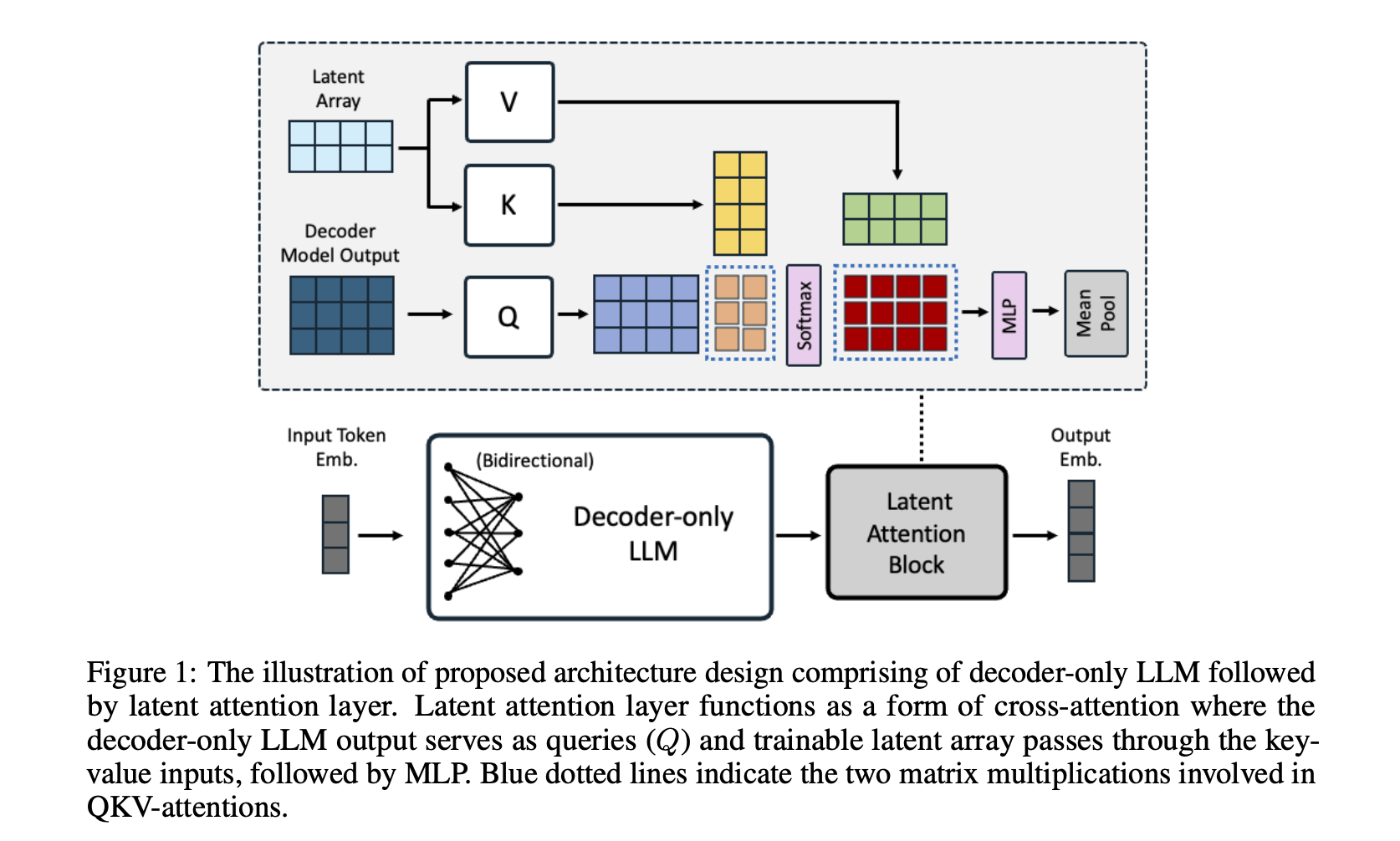
The NV-Embed paper proposes a few technical improvements. The first one is to remove the causal attention mask. When LLM is trained, a mask is used. This mask prevents LLM from information leakage. The idea is to show LLM only the data up to the current token and ask it to predict the next one. The mask hides the subsequent tokens from LLM. In the context of the embedding model, we can remove the mask, as we don't need to predict the next token. Another improvement from the paper is the use of a Latent Attention Layer. This layer improves the generation of embeddings from the tokens. Instead of taking averages of token embeddings or taking the last <EOS> token embedding, the NV-Embed model uses an additional attention layer.
References
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models - https://arxiv.org/abs/2405.17428
Gecko: Versatile Text Embeddings Distilled from Large Language Models - https://arxiv.org/abs/2403.20327