
Code with LLM

Maybe one day, LLMs will be writing all software and will completely replace humans in this, but today, they need human oversight. One thing has changed - AI coding assistants have taken their place in SDLC. We can argue about the impact of such tools and what gain we receive, but it looks like it will only grow.
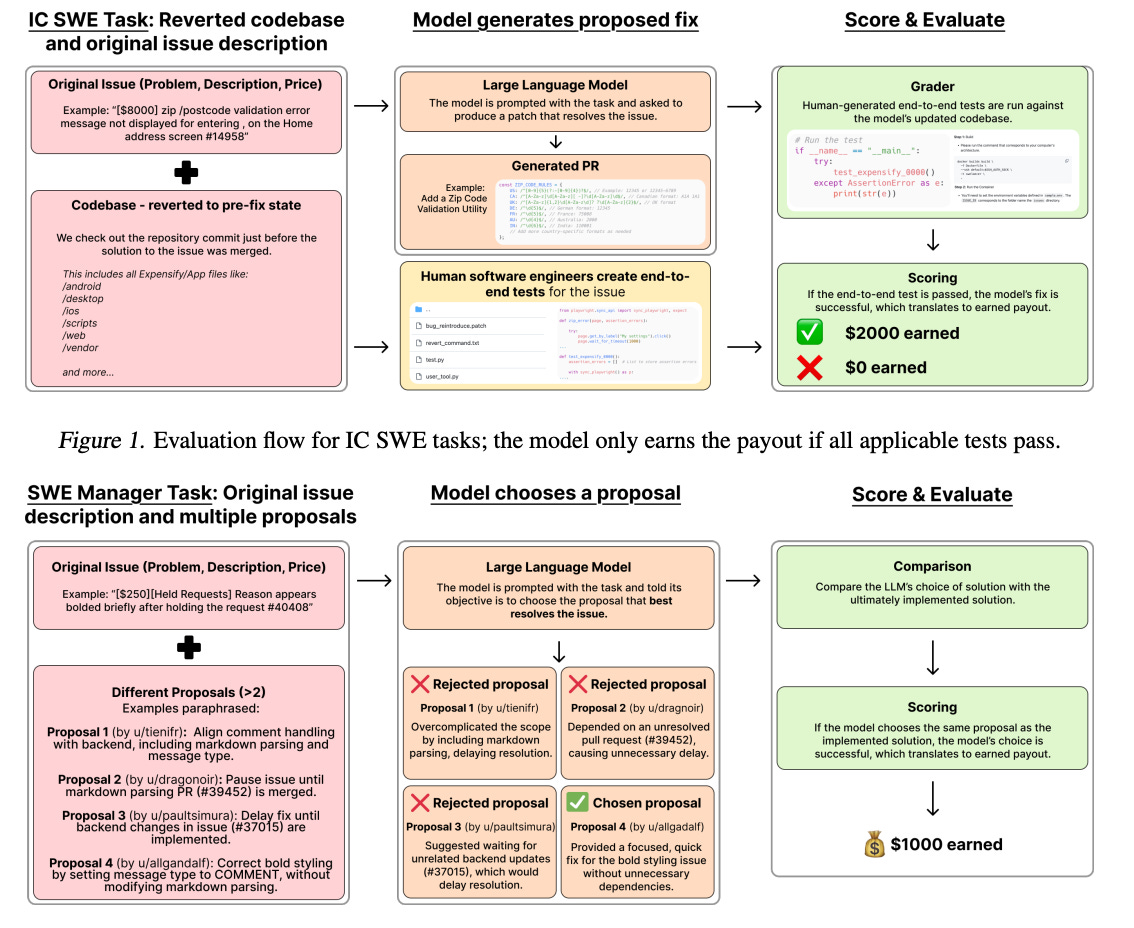
The easiest way to understand how well LLM can code is to use some benchmarks. The benchmark that has made a lot of buzz recently is SWE-Lancer. The paper tried to answer the question - Can LLM earn 1M USD as a freelance developer? No, not yet, but the benchmark sheds light on why it's hard to measure code generation quality. The authors took real-world problems and wrote end-to-end tests to measure the resulting solution. The winning model is Claude 3.5 Sonnet, which managed to hypothetically earn 400K USD. There was no real money involved in the competition. The paper didn't clarify the cost of running the experiment, but in any case, we should multiply this number by 7. 7 here is not a magic number. 7 attempts improved the resulting score by 2x
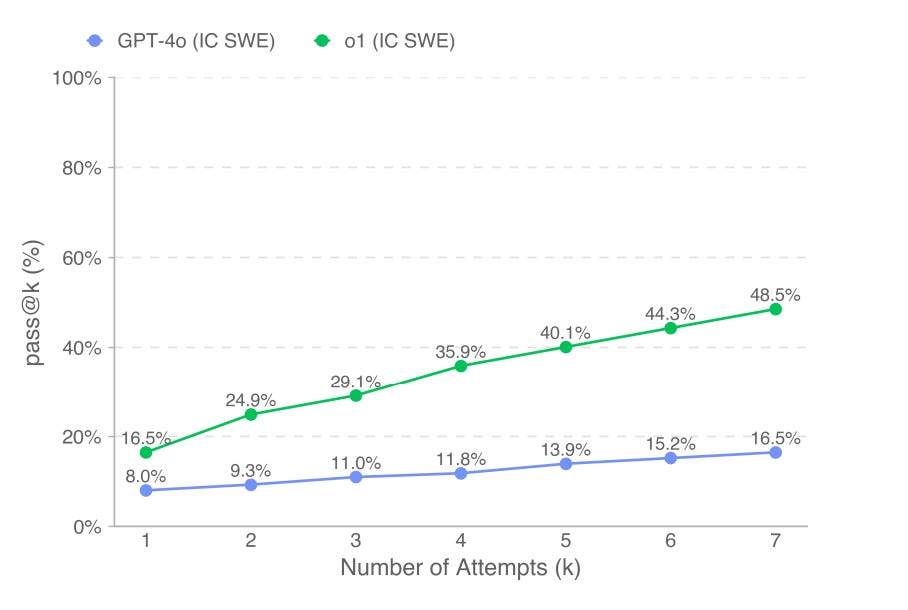
Another paper from OpenAI is Competitive Programming with LRM. The paper compares the results of o1, o1-ioi(a handcrafted model for competitive programming) and o3 in the International Olympiad in Informatics. The winning model is o3 with 2724 scores, o1-ioi - 2214 and o1 - 1673. On one side, it sounds like the model managed to beat humans in this exercise because o3 is in the top 99.8th percentile, but the real value of the paper is different. o1 is a model which was built to prove inference time scaling. o1-ioi is a fine-tuned version of o1, but o3 is the next generation of o1. Basically, o3 is an advanced general-purpose model which managed to beat domain-specific o1-ioi. Some may even say there is no value in building domain-specific models - just wait for the next generation of general-purpose ones.
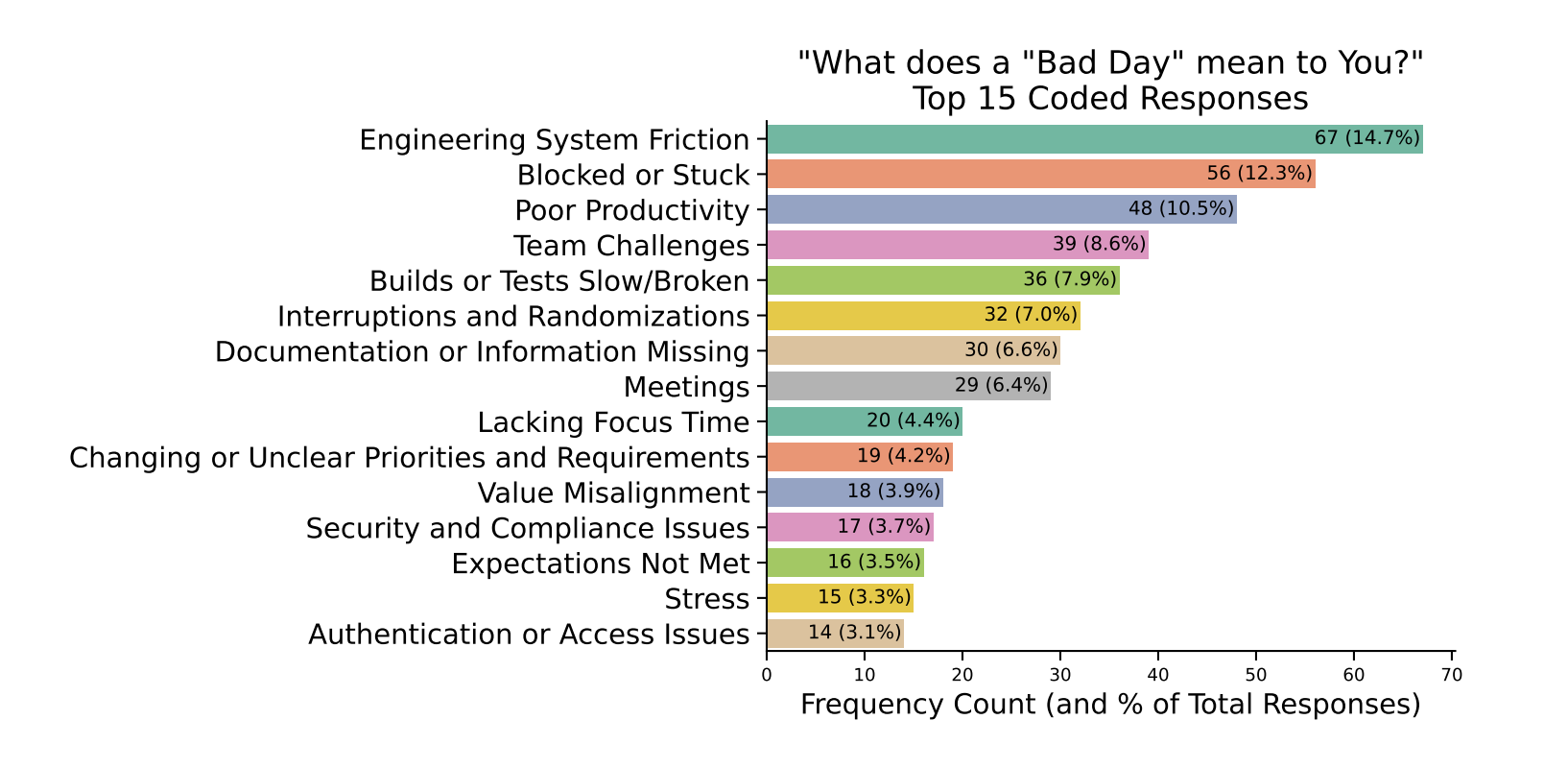
So LLM wins in isolated, well-defined tasks but needs humans for complex and context-dependent ones. It means that we need to analyse use cases in the life of a software engineer and propose LLM-based solutions. Microsoft has released the paper Identifying Factors Contributing to Bad Days for Software Developers. The paper found factors which negatively impact developer productivity: tooling and infrastructure(flaky tests, slow builds, poor dev tools, crashes), process inefficiencies(unclear ownership, lack of documentation, changing priorities) and team dynamics. The one thing that improves dev performance is the state of flow. This is where LLMs help a lot. AI suggestions and chat help keep the flow state, answer questions, reduce repetitive tasks, increase progress and eliminate context switches.
The primary stopper in adopting GenAI in general and coding assistants in specific is a lack of trust, as the AI Software Engineer paper states. By definition, trust requires results (later about this) and visibility of how the result was achieved. The paper focuses on the last - describing how we can help LLMs establish trust in coding: generate tests, formal proofs, security guardrails and write code with the same intent as the rest of the project.
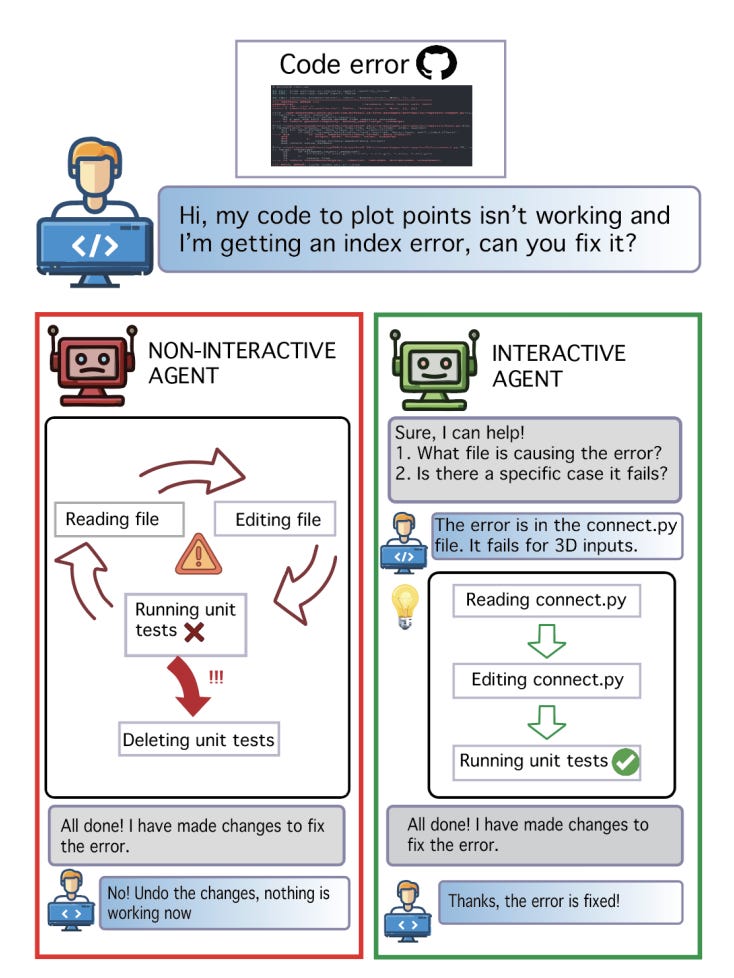
One of the problems for LLM in generating working code from a description is ambiguity - the paper Interactive Agents to Overcome Ambiguity in Software Engineering focuses precisely on this. The conducted experiment compared three prompts: full descriptions of a problem, summarized descriptions of a problem with hidden parts and interaction prompts. When we give the model a full description, we expect it to solve a problem for us. When we provide a summarized version we hope that the model will have problems generating code for us. In the last case, we give a model the ability to ask clarifying questions. Claude won this competition. Claude managed to solve more tasks, find ambiguity in a description and ask better questions to clarify the description.

The point of the paper is that the model needs a way to ask clarifying questions. LLM solves more problems if they can interact with the user. The paper proposed including this in a prompt and be ready to clarify something for the model. It sounds like the next frontier after Large Language and Large Reasoning Models is Large Questioning Models.
References:
Paper: SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering? - https://arxiv.org/abs/2502.12115
Paper: Competitive Programming with Large Reasoning Models - https://arxiv.org/abs/2502.06807v1
Paper: Identifying Factors Contributing to Bad Days for Software Developers: A Mixed Methods Study - https://www.arxiv.org/abs/2410.18379
Paper: AI Software Engineer: Programming with Trust - https://arxiv.org/abs/2502.13767
Paper: Interactive Agents to Overcome Ambiguity in Software Engineering - https://arxiv.org/abs/2502.13069