


Chasing OpenAI's o1 one month later

The o1 model from OpenAI was released in September of this year. This was the first model to focus on reasoning. Studies show that the model was built on the same next-token prediction approach, but o1 performs substantially better than previous models on math problems. The key to this performance boost is inference scaling, in other words, letting the model spend more time thinking. o1 introduced a new type of token—thinking tokens.
When we ask any LLM to generate an answer, there is a certain probability of receiving a correct response. The trick to improving our chances is to create many answers with different temperature settings. Even such a simple approach helps to improve some LLMs to an 85% success rate. But now we have two problems: how to generate candidates efficiently and choose the correct answer from different candidates (solutions).
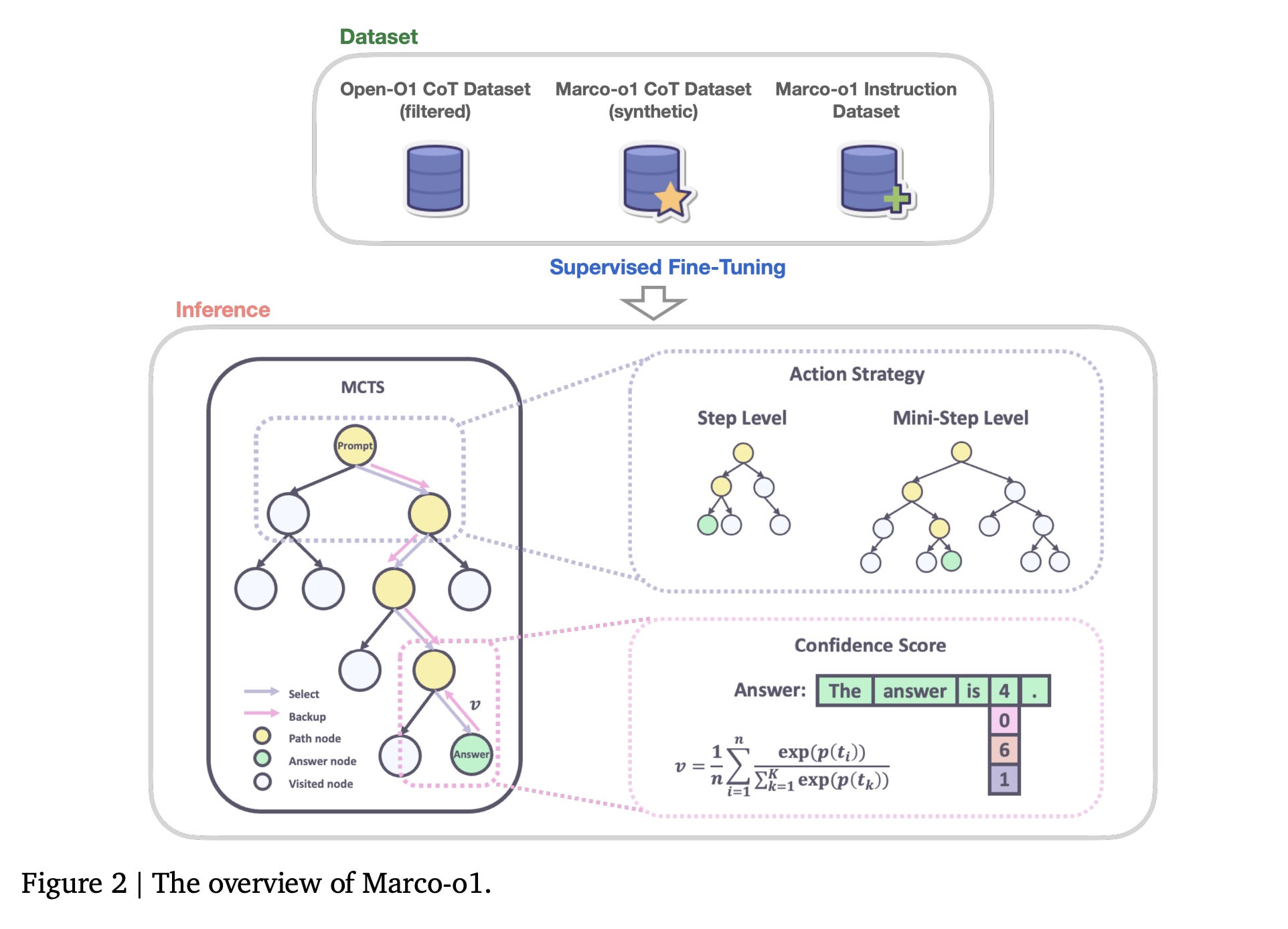
For instance, Marco-o1 (Open reasoning model from Alibaba) uses MCTS (Monte Carlo Tree Search) to generate reasoning chains. The idea of MCTS is to find a solution for a problem when it's not possible to use brute force. To implement MCTS, we must represent a problem as a tree, where each node represents a potential step. We aim to find a path in the tree that leads to a solution. In the LLM world, the tree's root is a prompt, and each node is a step in a reasoning path. To choose the best next node among siblings, we can use log probabilities, a technique I have previously covered. One last thing: MCTS was used in AlphaGo and successfully beat humans in the game of Go.
Once we have several solutions, we need to choose the best one. Alternatively, we can use collaborative verification to find the best solution instead of log probabilities. This method combines Chain-of-Thoughts and Program-of-Thoughts into CoTnPoT. The idea is to compare results from CoT to PoT. The method works as follows: a CoT solution is converted into PoT format with the help of a coding LLM. If the results do not match, we ignore the solution. If they match, we send them to the verifier.
To create a verifier, we need to fine-tune a model. In this case, we will use CoT fine-tuning. Good data sets with positive and negative CoT examples are a must for these types of models.
References:
Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions - https://arxiv.org/abs/2411.14405
LLaMA-Berry: Pairwise Optimization for O1-like Olympiad-Level Mathematical Reasoning - https://arxiv.org/abs/2410.02884
Improving LLM Reasoning through Scaling Inference Computation with Collaborative Verification - https://arxiv.org/abs/2410.05318
When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1 - https://arxiv.org/abs/2410.01792