


Autonomous AI agents with self-improvement capabilities


An AI Agent is an intelligent piece of software that solves a task in autonomous mode. The user gives the AI agent a task, and the AI Agent finds the best way to solve it. What is important here is that the user doesn't provide step-by-step instructions. The problem is that most AI Agents still use a hard-coded high-level algorithm inside, which prevents the agent to evolve. Wouldn't it be cool if AI Agents could self-improve?
In the basic form we can embed a feedback loop in the agent. Tencent AI Lab has shared the 'Cognitive Kernel' paper with exactly this approach. Cognitive Kernel is an open sourced dockerized implementation of generalist autopilot. The next step is to use a critic to self-improve without awaiting a feedback from the user.
But what we really need is to teach the agent to accumulate experience. The paper Self-Evolving GPT explains how to do this. In a nutshell, it proposes categorizing users' tasks and using task-specific memory when generating an answer. The core of the framework is Task-Specific Experience Memory. This module stores information for each task type. The stored information is a task name, description, procedure(steps for accomplishing a task) and suggestions(steps to generate high-quality responses) - the framework generates all these. When a new request from the user is received, the framework generates a name and description for it. Using name and description, we can find identical tasks in the memory and use this experience to generate the answer.
For a new task, the framework uses the Experience Transfer module to find similar tasks in memory and the Autonomous Practice module to generate examples based on similar tasks and web searches. The Experience Induction module finishes the learning process by updating the experience in memory.
The 'Large Language Models Can Self-Improve At Web Agent Tasks' paper proposes a different approach. The main idea is to use fine-tuning to extend the agent's capabilities. The paper shows how to generate synthetic training examples and use them for fine-tuning. As a result, this yields a 31% improvement over the non-fine-runed version. Compared to the previous approach, we need to update the algorithm for generating synthetic data every time we want to teach the agent new capabilities, leading to another fine-tuning.
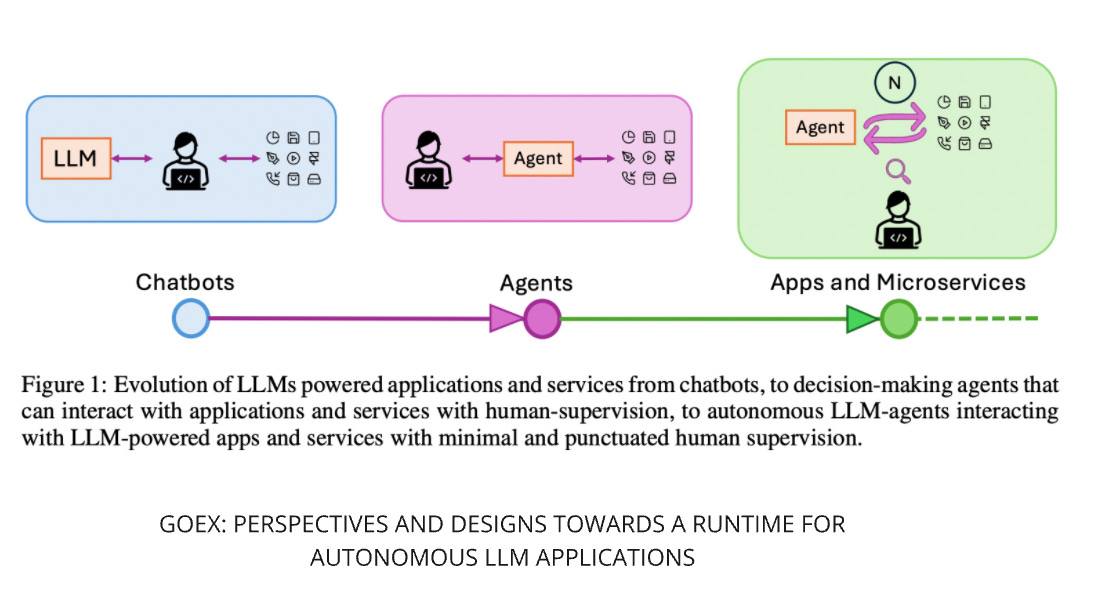
It doesn't matter which approach to choose for self-improved autonomous AI agents. The question of safety will be essential. If the agent decides to send an email to the wrong person, it might be quite painful. In order to improve this, new runtime safety mechanisms need to be created, such as described in the GoEX paper. The paper argues with the popular "pre-facto validation" which means to review agent's plan before execution and propose "post-facto validation" - verify actions after seeing the result of execution, which at first sounds dangerously. The core idea of the paper is to provide undo features and, if undo can not be provided, to think about damage confinement by restricting the agent's access to specific systems. I can only add an error budget to this list - a pattern from SRE teams.
References:
https://arxiv.org/abs/2407.08937v1 - Self-Evolving GPT: A Lifelong Autonomous Experiential Learner
https://arxiv.org/abs/2405.20309 - Large Language Models Can Self-Improve At Web Agent Tasks
https://arxiv.org/abs/2409.10277 - Cognitive Kernel: An Open-source Agent System towards Generalist Autopilots
https://arxiv.org/abs/2404.06921 - GoEX: Perspectives and Designs Towards a Runtime for Autonomous LLM Applications