
4 Architectures of Deep Research Agents

Deep Research is a feature of AI systems that helps users to do in-depth analysis of a selected topic. It works by analysing hundreds of online sources and providing a report at the end. Mainly, it is used for academic research, business intelligence or scientific discoveries. As I understand it now, I first encountered Deep Research in the Matrix movie, when Neo's computer was searching the Internet to find evidence of Morpheus while Neo was asleep.
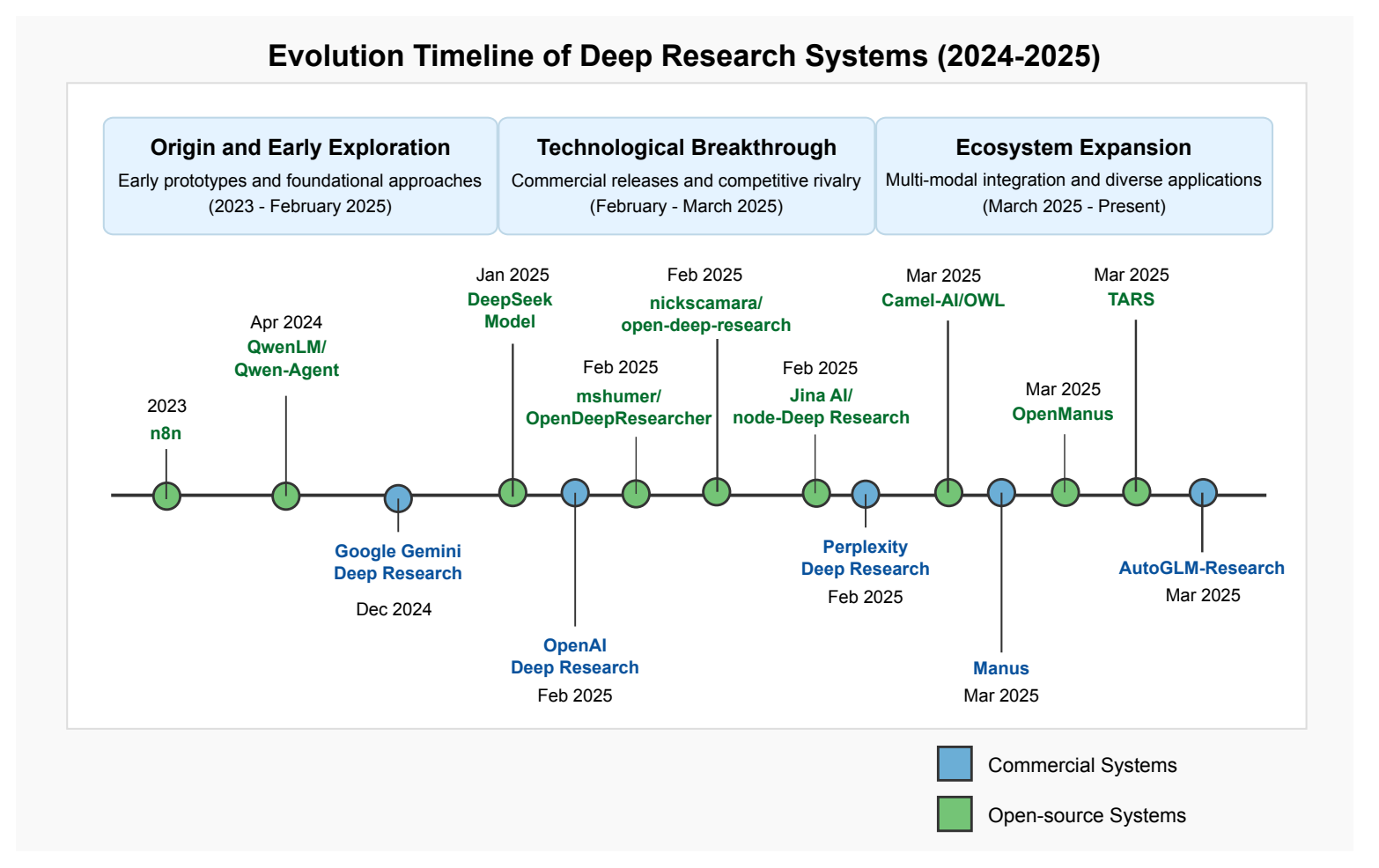
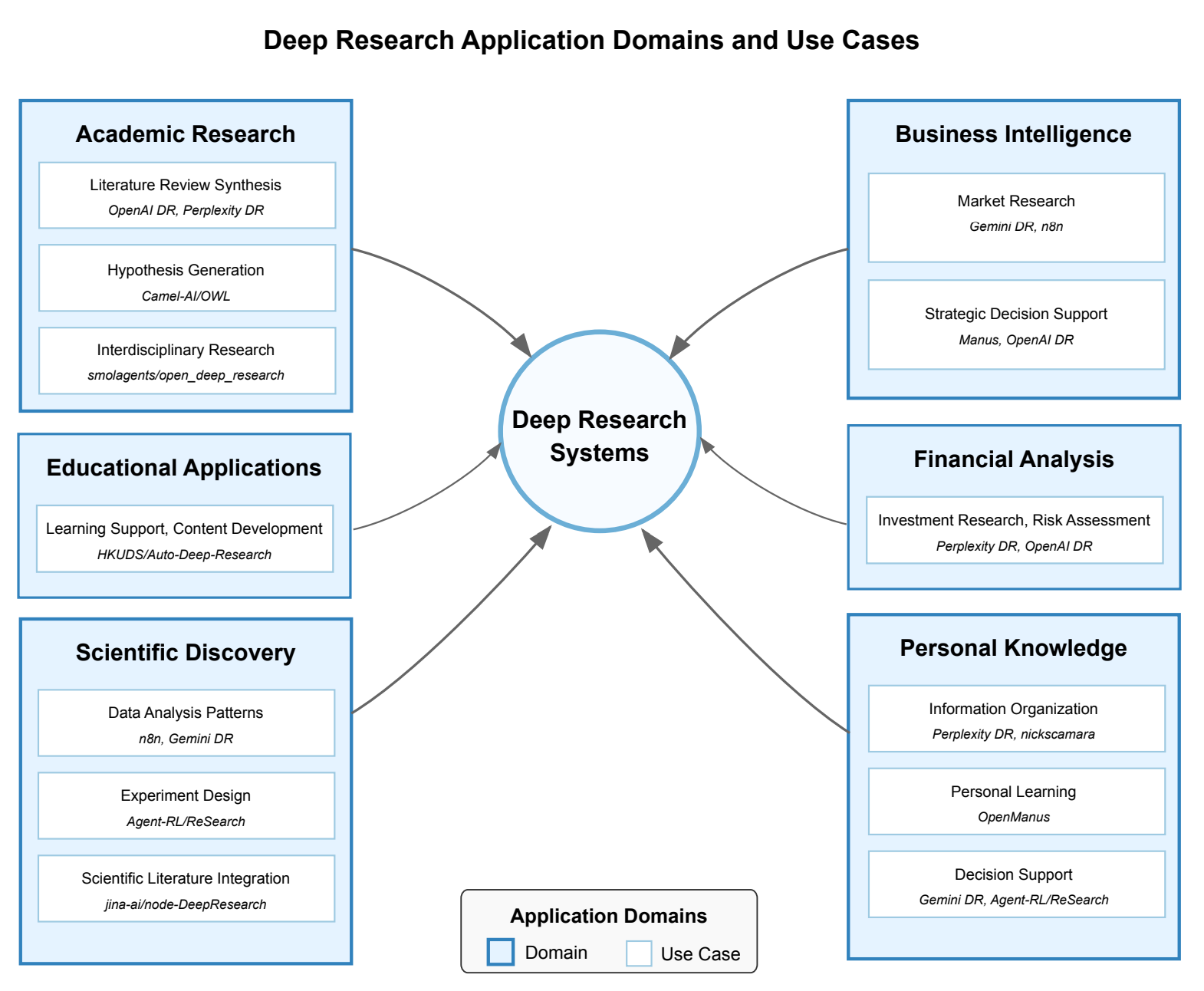
In the recent survey paper on the subject of Deep Research, four architectures were proposed: monolithic, pipeline-based, multi-agent and hybrid (combines elements from the previous 3). All of these architecture types consist of the same components: Foundation Model, Task Planning, Tools and API Integrations, Web Browsing, State Management (Memory), Source Evaluation (Validation, Fact Checking), and Output Generation. The difference is how these components are integrated and who controls the execution flow. In a nutshell, Deep Research receives the user's request, plans search queries, uses web browsing to find relevant content, examines the extracted content, and prepares a report.
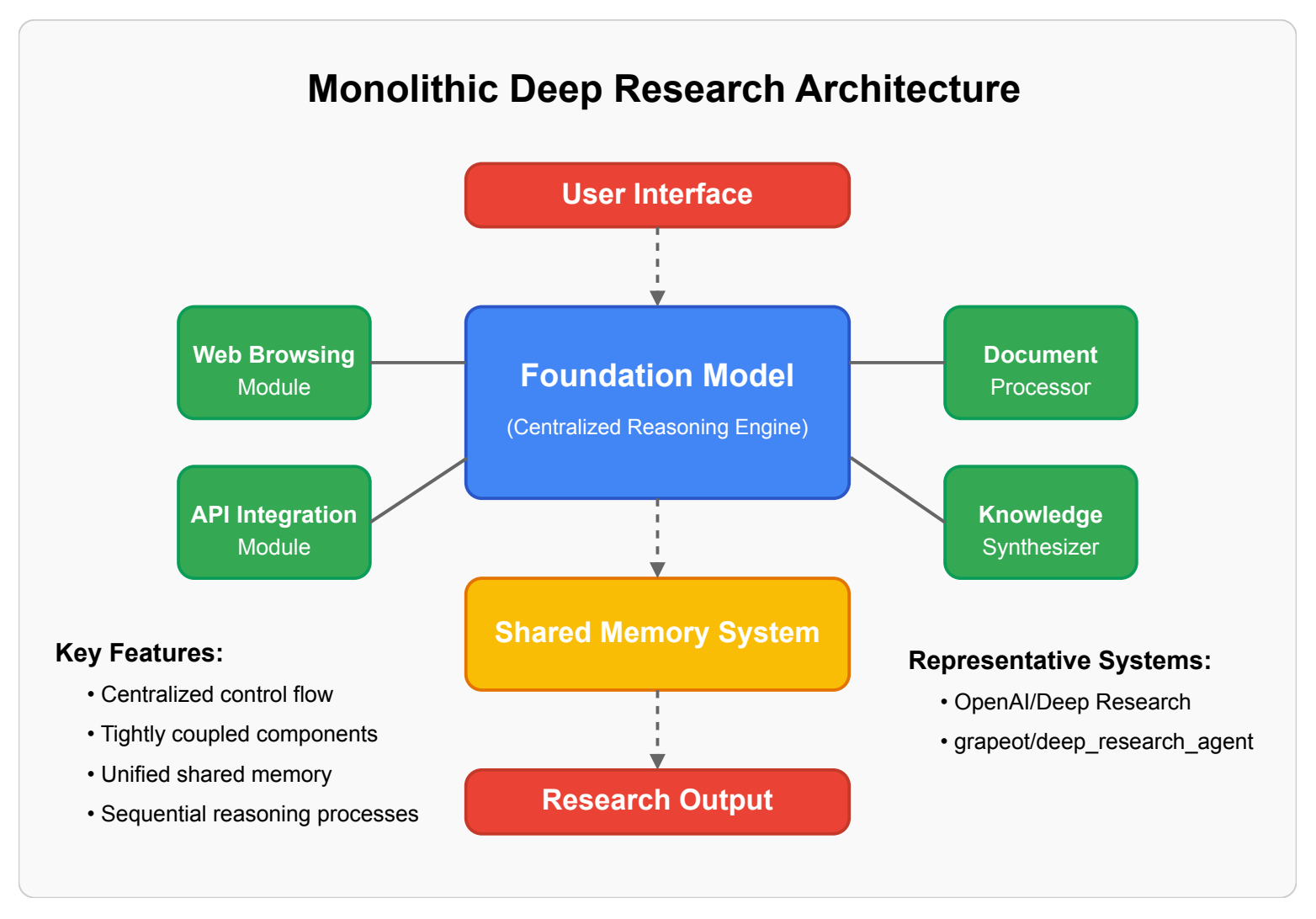
The Monolithic architecture requires integrating all components into the Foundation Model. The Foundation Model itself controls the execution flow. In this design, a single Foundation Model is typically used. All of the components are tightly integrated, which makes it hard to scale and extend. The quality of the final report is defined by how well the Model can use the tools. At the same time, this is the easiest architecture to implement and debug. Worth noting that this implementation offers a high reasoning coherence.
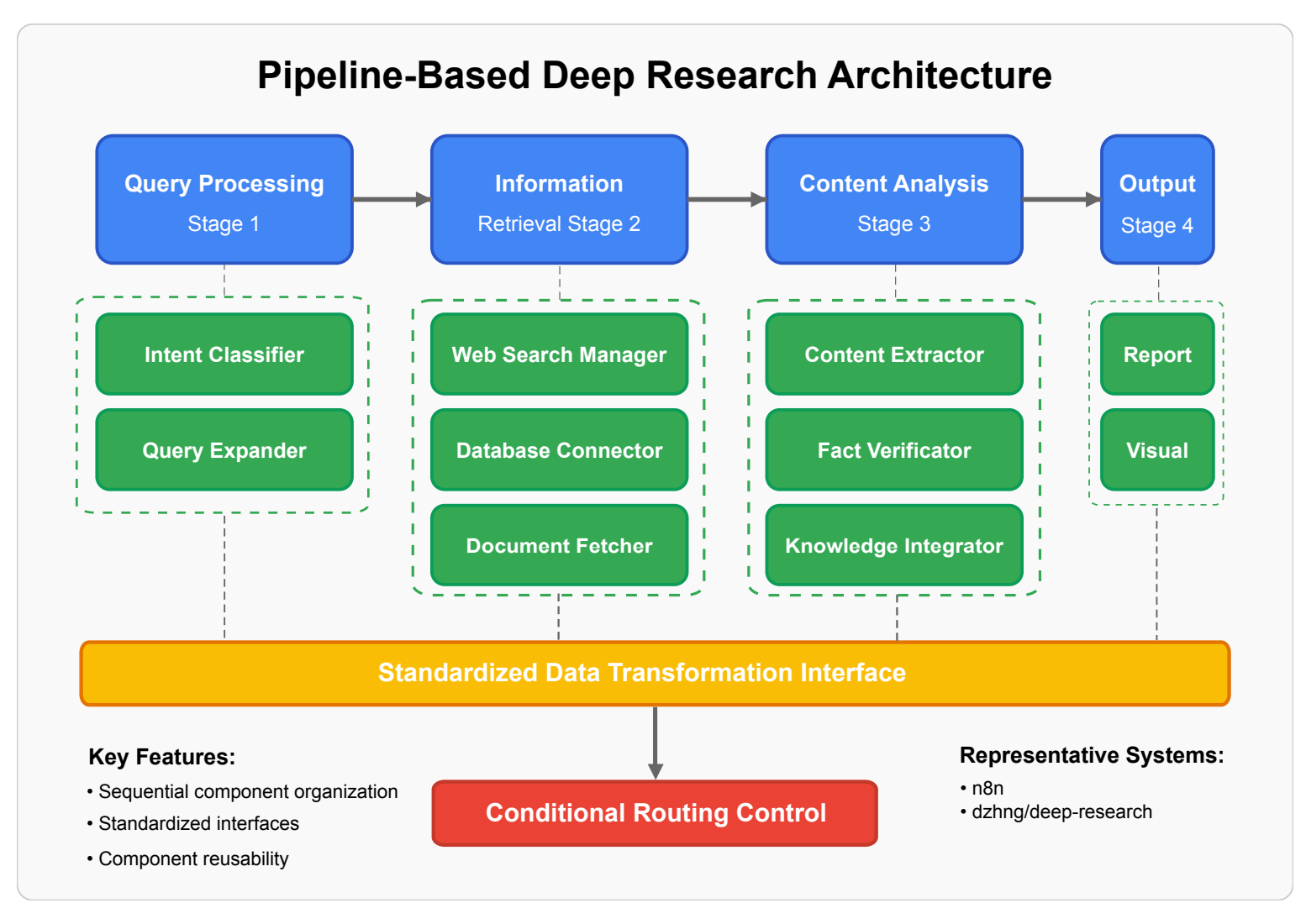
The next architecture is Pipeline-Based. As the name suggests, we define an execution pipeline. Each step in the pipeline focuses on a single job. The first step in the pipeline is Query Processing, which classifies intent and expands an initial query. The information retriever stage uses a browser to fetch content. Then, Content Analysis extracts and verifies facts. The last step is output generation. The pipeline architecture offers a highly modular design. The execution flow is controlled by the pipeline design itself. The significant advantage of this architecture is reproducibility.
The Multi-agent architecture consists of several agents that collaborate to produce the final answer. They all connected via a message bus and use separate memory instances. The execution flow here is fully dynamic and based on the Agents' specialisations. This architecture requires an Agent Coordination Layer.
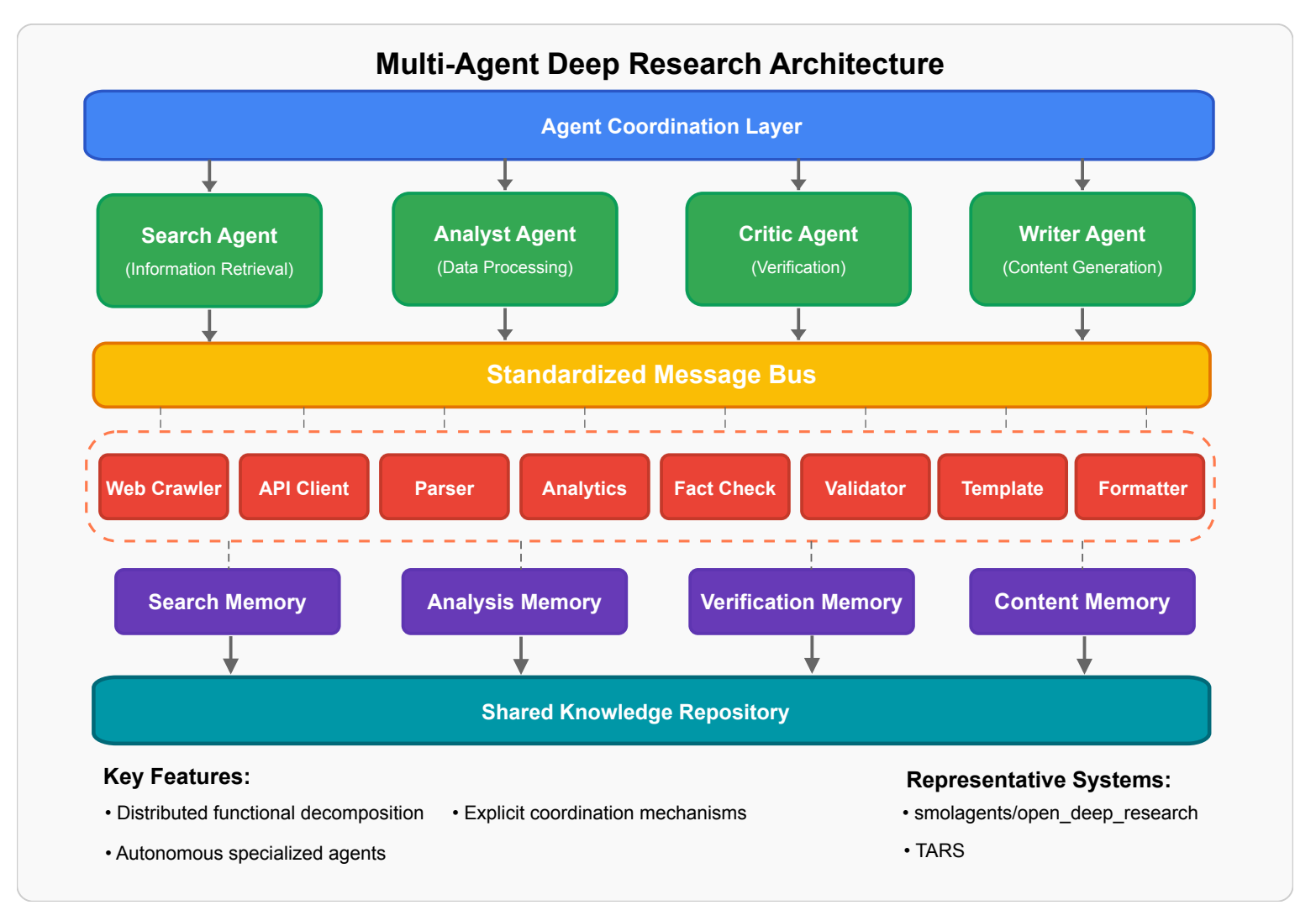
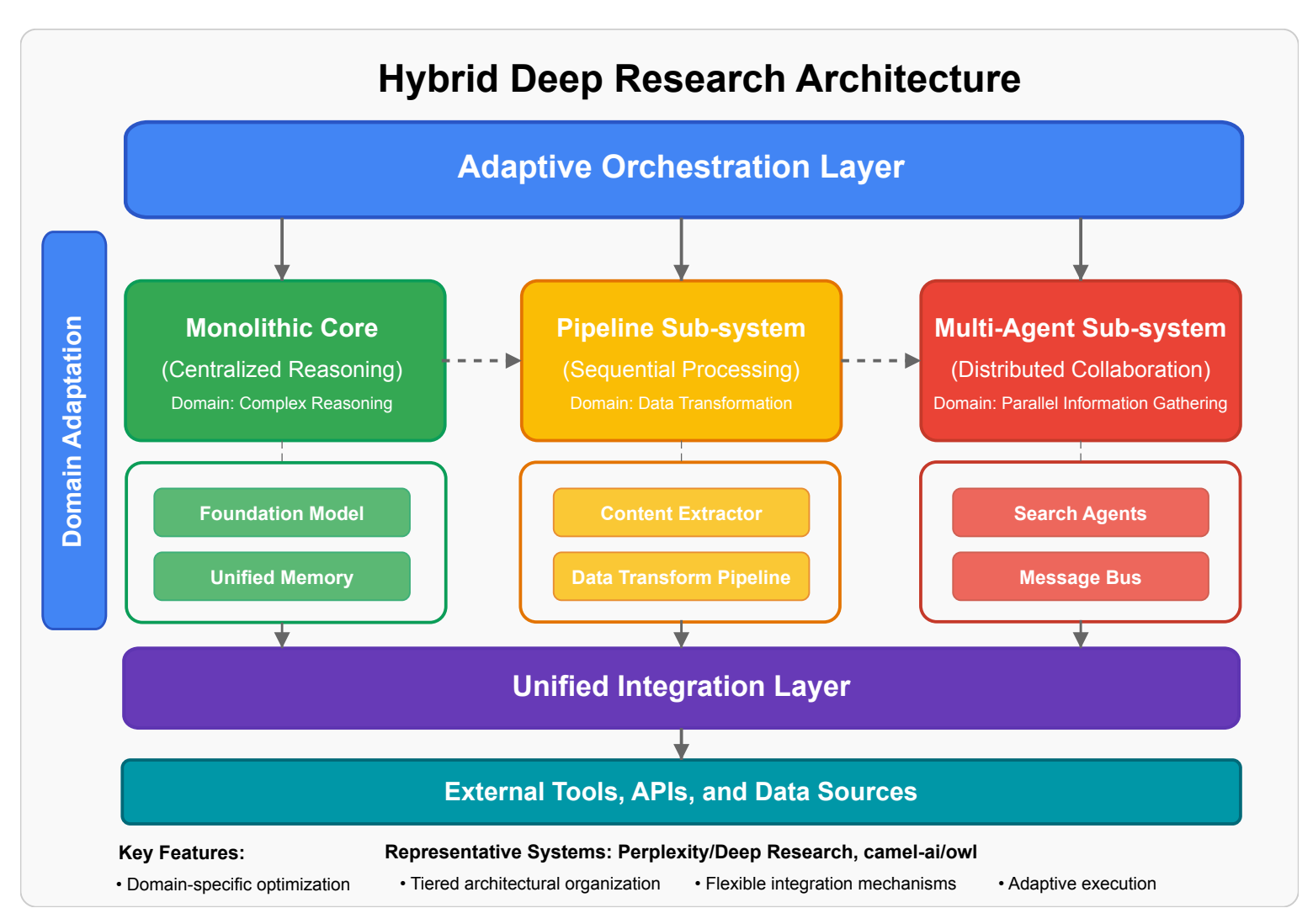
If you build a Deep Research product and need a quick result, the Monolithic architecture might be the best choice. In this case, you need to write custom tools and embed them into a prompt. Once the usage pattern is defined, you can switch to the Pipeline by splitting your tool usage by stages. The pipeline design restricts the types of research you can provide, so to improve flexibility, it makes sense to convert stages into separate agents - the Multi-agent architecture. And here is where you can start thinking about a hybrid approach. Use predefined-pipelines for well-known users' intents and new intents - Multi-agent.
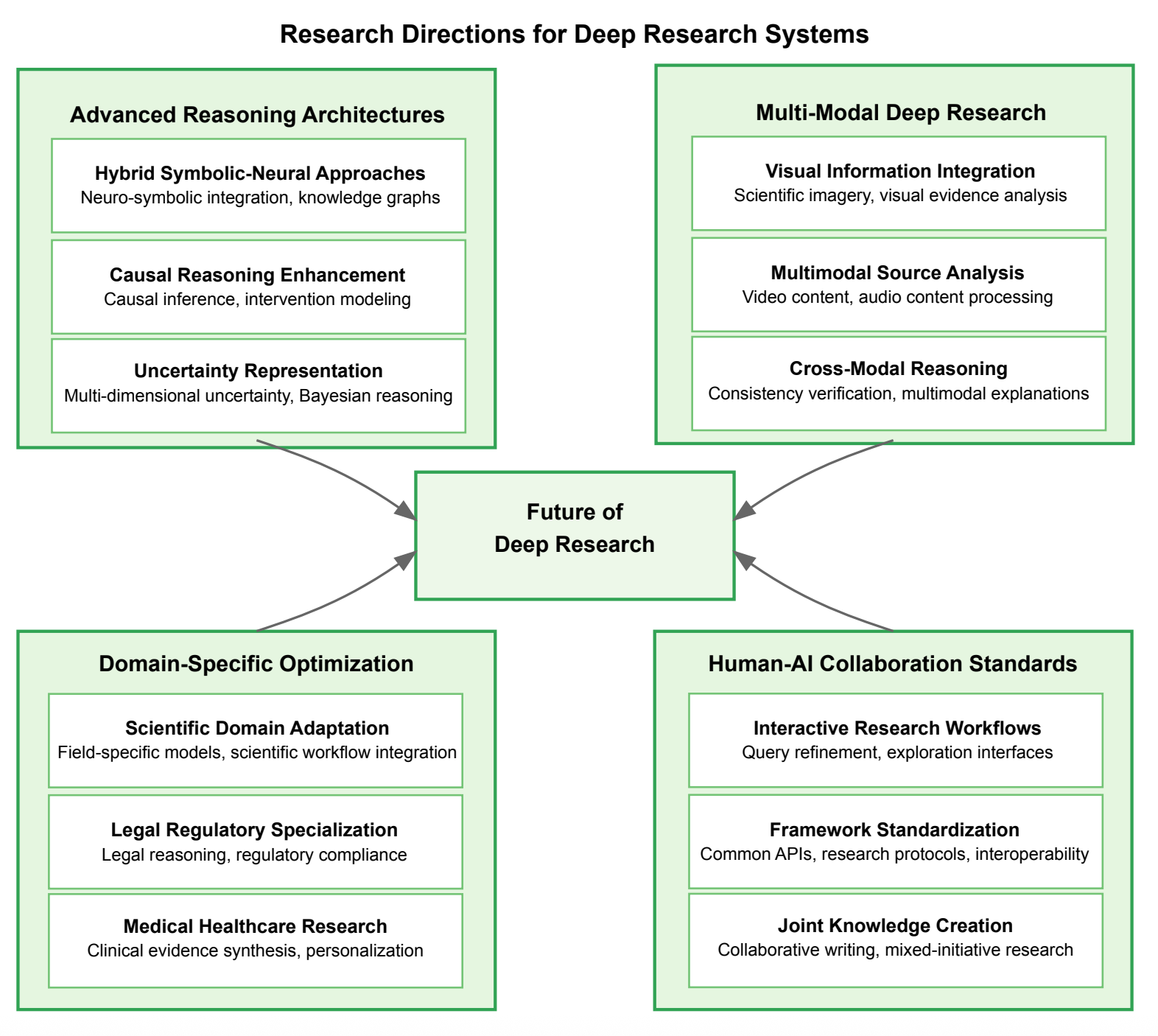
The paper reviewed 80 products and highlights potential future directions.
Resources:
Paper: A Comprehensive Survey of Deep Research: Systems, Methodologies, and Applications - https://www.arxiv.org/abs/2506.12594
Awesome Deep Research list - https://github.com/scienceaix/deepresearch